ebpf Basic Knowledge

Reference
https://arttnba3.cn/2023/05/31/EBPF_0X00/:适合入门了解ebpf
https://arthurchiao.art/blog/linux-socket-filtering-aka-bpf-zh/:介绍的很全面(包括ebpf的一些内部机制)
https://www.kernel.org/doc/html/latest/bpf/index.html:bpf 文档
https://ebpf.io/what-is-ebpf/:里面有一些 ebpf 相关的实验
eBPF学习笔记
定义
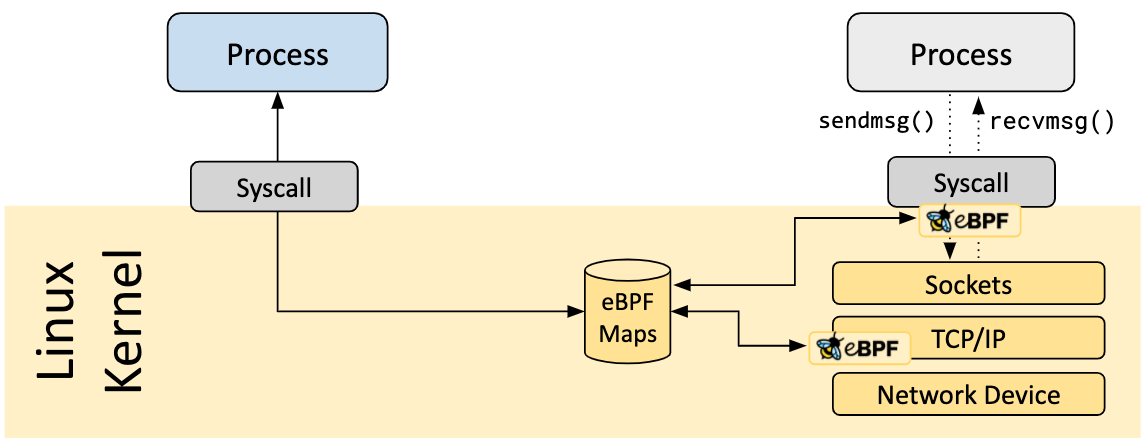
伯克利包过滤器(Berkeley Packet Filter)是一个 Linux kernel 中用以对来自于链路层的数据包进行过滤的架构,其位于内核中的架构如下图所示:
BPF 在内核中实现了一个新的虚拟机设计,通过即时编译(Just-In-Time compilation)技术将 BPF 指令翻译为 BPF 虚拟机的字节码,可以高效地工作在基于寄存器结构的 CPU 上
Linux kernel 自 3.18 版本起提供了扩展伯克利包过滤器(extended BPF,即 eBPF),其应用范围更广,能够被应用于更多的场景,原来的 BPF 被称为 classic BPF(cBPF),且目前基本上已经被废弃,Linux 会将 cBPF 字节码转化为 eBPF 字节码再执行
作为一个位于内核层面的虚拟机,eBPF 无疑为攻击者提供了相当大的新攻击面
基本架构
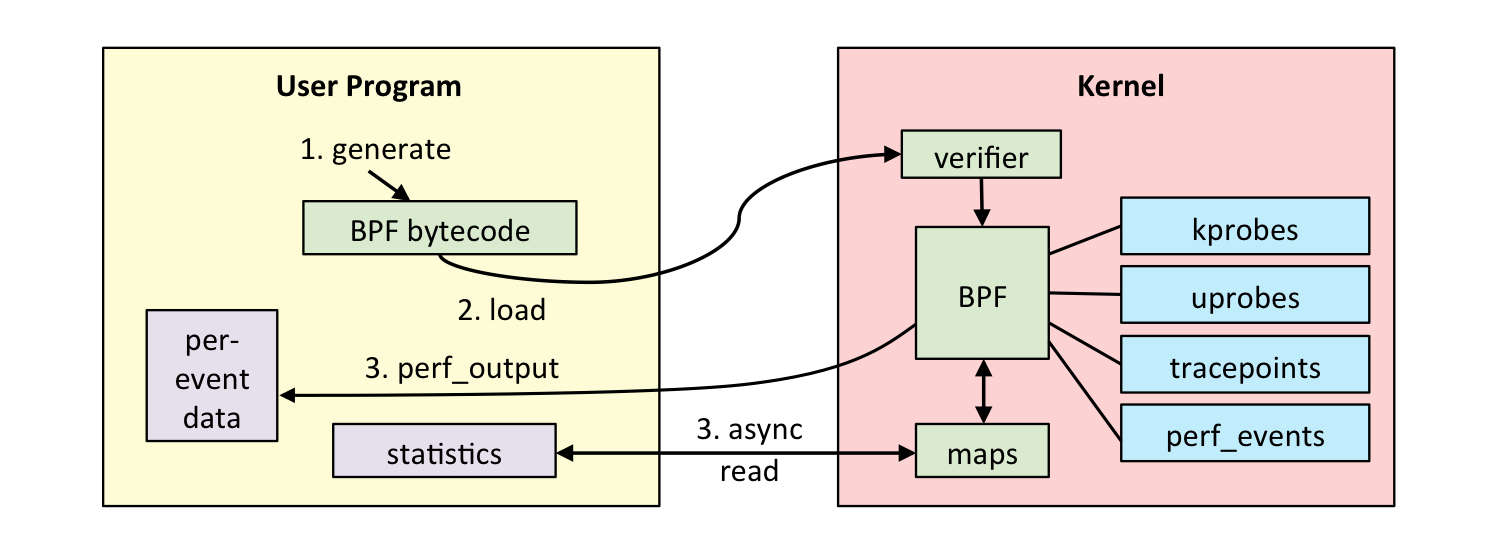
用户程序首先会被生成 BPF 字节码,然后被加载到内核,这时候内核通过 verifier对字节码程序进行安全性检查,通过检查后便通过 JIT 编译运行,eBPF 程序主要分为如下类型:
kprobes:内核中的动态跟踪,可以跟踪至内核中的函数入口或返回点uprobes:用户空间中的动态跟踪,与 kprobes 不同的是跟踪的函数位于用户程序中tracepoints:内核中的静态跟踪perf_events:定时采样与 PMC
注意事项:上图中的 map 作为用以保存数据的通用结构,可以在不同的 eBPF 程序之间或是用户进程与内核间共享数据
同一个eBPF程序可以附加到多个事件, 并且不同的eBPF程序可以访问同一个映射, 示意图如下
1 | tracing tracing tracing packet packet packet |
verifier
在 eBPF 字节码被传入到内核空间后,其首先需要经过 verifier 的安全检查,之后才能进行 JIT 编译,verifier 主要检查以下几点:
- 没有回向边(back edge)、环路(loop)、不可达(unreachable)指令
- 不能在指针之间进行比较,指针只能与标量进行加减(eBPF 中的标量值为不从指针派生的值),verifier 会追踪哪些寄存器包含指针、哪些寄存器包含标量值
- 指针运算不能离开一个 map 的“安全”边界,这意味着程序不能访问预定义的 map 外的内存,verifier 通过追踪每个寄存器值的上界与下界
- 不能将指针存储在 map 中或作为返回值,以避免将内核地址泄露到用户空间
ALU Sanitation
ALU Sanitation 是 eBPF 中一个代码加固与运行时动态检测的框架,通过对程序正在处理的实际值进行运行时检查以弥补 verifier 静态分析的不足,这项技术通过调用 fixup_bpf_calls() 为 eBPF 程序中的每一条指令的前面都添加上额外的辅助指令、替换部分指令等方式来实现
ebpf 虚拟机
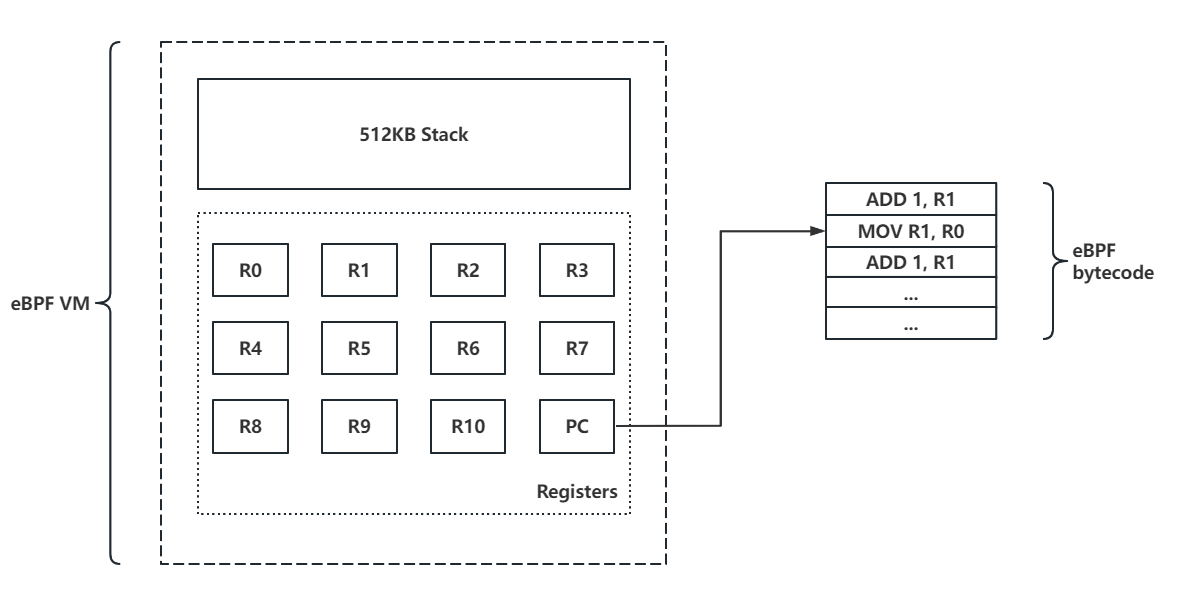
eBPF 虚拟机本质上是 RISC 架构,一共有 11 个 64 位寄存器,一个程序计数器(PC)与一个固定大小的堆栈(通常为 512KB),在 x86 架构下的对应关系如下:
| eBPF 寄存器 | 映射 x86_64 寄存器 | 用途 |
|---|---|---|
| R0 | rax | 函数返回值 |
| R1 | rdi | argv1 |
| R2 | rsi | argv2 |
| R3 | rdx | argv3 |
| R4 | rcx | argv4 |
| R5 | r8 | argv5 |
| R6 | rbx | callee 保存 |
| R7 | r13 | callee 保存 |
| R8 | r14 | callee 保存 |
| R9 | r15 | callee 保存 |
| R10(只读) | rbp | 堆栈指针寄存器 |
在 eBPF 中,一个寄存器的状态信息使用 bpf_reg_state 进行表示
1 | struct bpf_reg_state { |
寄存器运行时值与边界范围校验
eBPF 程序的安全主要是由 verifier 保证的,verifier 会模拟执行每一条指令并验证寄存器的值是否合法,主要关注这几个字段:
smin_value、smax_value: 64 位有符号的值的可能取值边界umin_value、umax_value:64 位无符号的值的可能取值边界s32_min_value、s32_max_value:32 位有符号的值的可能取值边界u32_min_value、u32_max_value:32 位无符号的值的可能取值边界
而寄存器中可以确定的值实际上通过 var_off 字段进行表示,该值用一个 tnum 结构体表示,mask 中为 0 对应的 value 位为已知位:
1 | struct tnum { |
一个 verifier 完全未知的寄存器如下:
1 | const struct tnum tnum_unknown = { .value = 0, .mask = -1 }; |
注意事项:需要注意的是寄存器边界值是 verifier 通过模拟执行推测出来的,运行时的寄存器值不一定与 verifier 所推测的一致,这也曾是很多 eBPF 漏洞产生的原因
寄存器类型
寄存器在程序运行的不同阶段可能存放着不同类型的值,verifier 通过跟踪寄存器值的类型来防止越界访问的发生,主要有三类:
- 未初始化(not init):寄存器的初始状态,尚未经过任何赋值操作,此类寄存器不能参与运算
- 标量值(scalar):该寄存器被赋予了整型值,此类寄存器不能被作为指针进行内存访问
- 指针类型(pointer):该寄存器为一个指针,verifier 会检查内存访问是否超出指针允许的范围
1 | /* types of values stored in eBPF registers */ |
eBPF 指令与 eBPF 程序
eBPF 为 RISC 指令集,单条 eBPF 指令在内核中定义为一个 bpf_insn 结构体:
1 | struct bpf_insn { |
相应地,一个最简单的 eBPF 程序便是一个 bpf_insn 结构体数组,我们可以直接在用户态下编写形如这样的结构体数组来描述一个 eBPF 程序,并作为 eBPF 程序字节码传入内核:
1 |
|
载入到内核中后,内核最终会使用一个 bpf_prog 结构体来表示一个 eBPF 程序:
1 | struct bpf_prog { |
eBPF map
bpf map 是一个通用的用以储存不同种类数据的结构,用以在用户进程与 eBPF 程序、eBPF 程序与 eBPF 程序之间进行数据共享,这些数据以二进制形式储存,因此用户在创建时只需要指定 key 与 value 的 size
bpf map 主要有以下五个基本属性:
type:map 的数据结构类型key_size:以字节为单位的用以索引一个元素的 key 的 size(在数组映射中使用)value_size:以字节为单位的每个元素的 sizemax_entries:map 中 entries 的最大数量map_flags:描述 map 的独特特征,例如是否整个 map 的内存应被预先分配等
1 | struct bpf_map { |
map 类型
可选 map 类型如下:
1 | enum bpf_map_type { |
常用的主要是以下几种类型:
BPF_MAP_TYPE_HASH:以哈希表形式存储键值对,比较常规BPF_MAP_TYPE_ARRAY:以数组形式存储键值对,key 即为数组下标,对应的 value 皆初始化为 0BPF_MAP_TYPE_PROG_ARRAY:特殊的数组映射,value 为其他 eBPF 程序的文件描述符BPF_MAP_TYPE_STACK:以栈形式存储数据
bpf 系统调用
所有的操作其实都是通过 bpf 系统调用来完成的,其原型如下:
1 | int bpf(int cmd, union bpf_attr *attr, unsigned int size); |
bpf_attr 结构体
bpf 系统调用中的第二个参数是指向联合体 bpf_attr 的指针,定义于 kernel/bpf/syscall.c 中如下,对于不同的 cmd 而言其含义不同,因此这里是一个由多个结构体构成的联合体:
1 | union bpf_attr { |
eBPF 指令格式
eBPF 单条指令长度固定为 8 字节,定义如下
1 | struct bpf_insn { |
而 eBPF 实际上有两种编码模式:
- 基础编码,单条指令为 64 bit
- 宽指令编码, 在基础编码后添加一个 64bit 的立即数 ,单条指令为 128 bit
基础编码的指令格式如下:
| 长度 | 8 bits | 4 bits | 4 bits | 16 bits | 32 bits |
|---|---|---|---|---|---|
| 含义 | opcode(操作码) | dst_reg(目的寄存器) | src_reg(源寄存器) | off(有符号偏移) | imm(有符号32位立即数) |
eBPF 指令中的 opcode 域长度为 8 bit,其中低 3 位固定表示指令类型,剩下的高 5 位根据类型不同用途也不同
指令类型如下表所示:
| 类型 | 值 | 描述 |
|---|---|---|
| BPF_LD | 0x00 | 只能用于宽指令,从 imm64 中加载数据到寄存器 |
| BPF_LDX | 0x01 | 从内存中加载数据到 dst_reg |
| BPF_ST | 0x02 | 把 imm32 数据保存到内存中 |
| BPF_STX | 0x03 | 把 src_reg 寄存器数据保存到内存 |
| BPF_ALU | 0x04 | 32bit 算术运算 |
| BPF_JMP | 0x05 | 64bit 跳转操作 |
| BPF_JMP32 | 0x06 | 32bit 跳转操作 |
| BPF_ALU64 | 0x07 | 64bit 算术运算 |
算术 & 跳转指令
对于算术 & 跳转指令而言由高位到低位分为三个部分:
| 4 bit | 1 bit | 3 bit |
|---|---|---|
| operation code (操作代码) | source(源) | instruction class (指令类型) |
① 操作代码
opcode 的最高 4 bit 用来保存操作代码,对于算术指令而言有如下类型:
| 指令类型 | 操作代码 | 值 | 描述 |
|---|---|---|---|
| BPF_ALU / BPF_ALU64 | BPF_ADD | 0x00 | dst += src |
| BPF_ALU / BPF_ALU64 | BPF_SUB | 0x10 | dst -= src |
| BPF_ALU / BPF_ALU64 | BPF_MUL | 0x20 | dst *= src |
| BPF_ALU / BPF_ALU64 | BPF_DIV | 0x30 | dst /= src |
| BPF_ALU / BPF_ALU64 | BPF_OR | 0x40 | dst |= src |
| BPF_ALU / BPF_ALU64 | BPF_AND | 0x50 | dst &= src |
| BPF_ALU / BPF_ALU64 | BPF_LSH | 0x60 | dst <<= src |
| BPF_ALU / BPF_ALU64 | BPF_RSH | 0x70 | dst >>= src |
| BPF_ALU / BPF_ALU64 | BPF_NEG | 0x80 | dst = ~src |
| BPF_ALU / BPF_ALU64 | BPF_MOD | 0x90 | dst %= src |
| BPF_ALU / BPF_ALU64 | BPF_XOR | 0xA0 | dst ^= src |
| BPF_ALU / BPF_ALU64 | BPF_MOV | 0xB0 | dst = src |
| BPF_ALU / BPF_ALU64 | BPF_ARSH | 0xC0 | 算术右移操作(正数补 0 负数补 1 ) |
| BPF_ALU / BPF_ALU64 | BPF_END | 0xD0 | 字节序转换 |
对于跳转指令而言有如下类型:
| 指令类型 | 操作代码 | 值 | 描述 | 备注 |
|---|---|---|---|---|
| BPF_JMP | BPF_JA | 0x00 | PC += off | 仅用于 BPF_JMP |
| BPF_JMP / BPF_JMP64 | BPF_JEQ | 0x10 | PC += off if dst == src | |
| BPF_JMP / BPF_JMP64 | BPF_JGT | 0x20 | PC += off if dst > src | |
| BPF_JMP / BPF_JMP64 | BPF_JGE | 0x30 | PC += off if dst >= src | |
| BPF_JMP / BPF_JMP64 | BPF_JSET | 0x40 | PC += off if dst & src | |
| BPF_JMP / BPF_JMP64 | BPF_JNE | 0x50 | PC += off if dst != src | 仅 eBPF:不等时跳转 |
| BPF_JMP / BPF_JMP64 | BPF_JSGT | 0x60 | PC += off if dst > src | 仅 eBPF:有符号 ‘>’ |
| BPF_JMP / BPF_JMP64 | BPF_JSGE | 0x70 | PC += off if dst >= src | 仅 eBPF:有符号 ‘>=’ |
| BPF_JMP / BPF_JMP64 | BPF_CALL | 0x80 | 函数调用 | 仅 eBPF:函数调用 |
| BPF_JMP / BPF_JMP64 | BPF_EXIT | 0x90 | 函数或者程序返回 | 仅 eBPF:函数返回 |
| BPF_JMP / BPF_JMP64 | BPF_JLT | 0xA0 | PC += off if dst < src | 仅 eBPF:无符号 ‘<’ |
| BPF_JMP / BPF_JMP64 | BPF_JLE | 0xB0 | PC += off if dst <= src | 仅 eBPF:无符号 ‘<=’ |
| BPF_JMP / BPF_JMP64 | BPF_JSLT | 0xC0 | PC += off if dst < src | 仅 eBPF:有符号 ‘<’ |
| BPF_JMP / BPF_JMP64 | BPF_JSLE | 0xD0 | PC += off if dst <= src | 仅 eBPF:有符号 ‘<=’ |
② 源
opcode 中间的一个 bit 用来表示 源 ,对于普通的跳转与算术指令而言含义如下表:
| 指令类型 | 源 | 值 | 描述 |
|---|---|---|---|
| BPF_ALU / BPF_ALU64 / BPF_JMP / BPF_JMP64 | BPF_K | 0x00 | 使用32-bit imm32 作为源操作数 |
| BPF_ALU / BPF_ALU64 / BPF_JMP / BPF_JMP64 | BPF_X | 0x08 | 使用源寄存器 (src_reg) 作为源操作数 |
对于 BPF_END 操作码而言含义如下:
| 指令类型 | 操作代码 | 源 | 值 | 描述 |
|---|---|---|---|---|
| BPF_ALU / BPF_ALU64 | BPF_END | BPF_TO_LE | 0x00 | 转为小端序 |
| BPF_ALU / BPF_ALU64 | BPF_END | BPF_TO_BE | 0x08 | 转为大端序 |
Load & Store 指令
对于 Load & Store 指令而言,opcode 由高到低分为如下三部分:
| 3 bits | 2 bit | 3 bits |
|---|---|---|
| mode(模式) | size(大小) | instruction class (指令类型) |
① 大小
Load & Store 指令的 size 域用来表示操作的字节数:
不知道为啥排序设为 4 2 1 8 :(
| 大小 | 值 | 描述 |
|---|---|---|
| BPF_W | 0x00 | 单字(4 字节) |
| BPF_H | 0x08 | 半字(2字节) |
| BPF_B | 0x10 | 单字节(1字节) |
| BPF_DW | 0x18 | 双字(8字节) |
② 模式
Load & Store 指令的 mode 域用来表示操作的模式,也就是如何去操作指定大小的数据:
| 模式 | 值 | 描述 | 备注 |
|---|---|---|---|
| BPF_IMM | 0x00 | 64 位立即数 | eBPF 为64 位立即数,cBPF 中为 32 位 |
| BPF_ABS | 0x20 | 数据包直接访问 | 兼容自 cBPF 指令。R6 作为隐式输入,存放 struct *sk_buff ;R0 作为隐式输出,存放包中读出数据;R1 ~ R5 作为 scratch registers,在每次调用后会被清空 |
| BPF_IND | 0x40 | 数据包间接访问 | 同 BPF_ABS |
| BPF_MEM | 0x60 | 赋值给 *(size *)(dst_reg + off) | 标准 load & store 操作 |
| BPF_LEN | 0x80 | 保留指令 | 仅用于 cBPF |
| BPF_MSH | 0xA0 | 保留指令 | 仅用于 cBPF |
| BPF_XADD | 0xC0 | 原子操作,*(无符号类型 *)(dst_reg + off16) 运算= src_reg | 仅用于 eBPF,不支持 1 / 2 字节曹祖 |
对于 BPF_XADD, imm32 域被用来表示原子操作的运算类型:
| imm32 | 值 | 描述 |
|---|---|---|
| BPF_ADD | 0x00 | 原子加 |
| BPF_OR | 0x40 | 原子或 |
| BPF_AND | 0x50 | 原子与 |
| BPF_XOR | 0xa0 | 原子异或 |
这里尽可能列出所有组合后的命令。
ALU Instructions
64-bit
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x07 | add dst, imm | dst += imm |
| 0x0f | add dst, src | dst += src |
| 0x17 | sub dst, imm | dst -= imm |
| 0x1f | sub dst, src | dst -= src |
| 0x27 | mul dst, imm | dst *= imm |
| 0x2f | mul dst, src | dst *= src |
| 0x37 | div dst, imm | dst /= imm |
| 0x3f | div dst, src | dst /= src |
| 0x47 | or dst, imm | dst |= imm |
| 0x4f | or dst, src | dst |= src |
| 0x57 | and dst, imm | dst &= imm |
| 0x5f | and dst, src | dst &= src |
| 0x67 | lsh dst, imm | dst <<= imm |
| 0x6f | lsh dst, src | dst <<= src |
| 0x77 | rsh dst, imm | dst >>= imm (logical) |
| 0x7f | rsh dst, src | dst >>= src (logical) |
| 0x87 | neg dst | dst = -dst |
| 0x97 | mod dst, imm | dst %= imm |
| 0x9f | mod dst, src | dst %= src |
| 0xa7 | xor dst, imm | dst ^= imm |
| 0xaf | xor dst, src | dst ^= src |
| 0xb7 | mov dst, imm | dst = imm |
| 0xbf | mov dst, src | dst = src |
| 0xc7 | arsh dst, imm | dst >>= imm (arithmetic) |
| 0xcf | arsh dst, src | dst >>= src (arithmetic) |
32-bit
These instructions use only the lower 32 bits of their operands and zero the
upper 32 bits of the destination register.
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x04 | add32 dst, imm | dst += imm |
| 0x0c | add32 dst, src | dst += src |
| 0x14 | sub32 dst, imm | dst -= imm |
| 0x1c | sub32 dst, src | dst -= src |
| 0x24 | mul32 dst, imm | dst *= imm |
| 0x2c | mul32 dst, src | dst *= src |
| 0x34 | div32 dst, imm | dst /= imm |
| 0x3c | div32 dst, src | dst /= src |
| 0x44 | or32 dst, imm | dst |= imm |
| 0x4c | or32 dst, src | dst |= src |
| 0x54 | and32 dst, imm | dst &= imm |
| 0x5c | and32 dst, src | dst &= src |
| 0x64 | lsh32 dst, imm | dst <<= imm |
| 0x6c | lsh32 dst, src | dst <<= src |
| 0x74 | rsh32 dst, imm | dst >>= imm (logical) |
| 0x7c | rsh32 dst, src | dst >>= src (logical) |
| 0x84 | neg32 dst | dst = -dst |
| 0x94 | mod32 dst, imm | dst %= imm |
| 0x9c | mod32 dst, src | dst %= src |
| 0xa4 | xor32 dst, imm | dst ^= imm |
| 0xac | xor32 dst, src | dst ^= src |
| 0xb4 | mov32 dst, imm | dst = imm |
| 0xbc | mov32 dst, src | dst = src |
| 0xc4 | arsh32 dst, imm | dst >>= imm (arithmetic) |
| 0xcc | arsh32 dst, src | dst >>= src (arithmetic) |
Byteswap instructions
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0xd4 (imm == 16) | le16 dst | dst = htole16(dst) |
| 0xd4 (imm == 32) | le32 dst | dst = htole32(dst) |
| 0xd4 (imm == 64) | le64 dst | dst = htole64(dst) |
| 0xdc (imm == 16) | be16 dst | dst = htobe16(dst) |
| 0xdc (imm == 32) | be32 dst | dst = htobe32(dst) |
| 0xdc (imm == 64) | be64 dst | dst = htobe64(dst) |
Memory Instructions
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x18 | lddw dst, imm | dst = imm |
| 0x20 | ldabsw src, dst, imm | See kernel documentation |
| 0x28 | ldabsh src, dst, imm | … |
| 0x30 | ldabsb src, dst, imm | … |
| 0x38 | ldabsdw src, dst, imm | … |
| 0x40 | ldindw src, dst, imm | … |
| 0x48 | ldindh src, dst, imm | … |
| 0x50 | ldindb src, dst, imm | … |
| 0x58 | ldinddw src, dst, imm | … |
| 0x61 | ldxw dst, [src+off] | dst = *(uint32_t *) (src + off) |
| 0x69 | ldxh dst, [src+off] | dst = *(uint16_t *) (src + off) |
| 0x71 | ldxb dst, [src+off] | dst = *(uint8_t *) (src + off) |
| 0x79 | ldxdw dst, [src+off] | dst = *(uint64_t *) (src + off) |
| 0x62 | stw [dst+off], imm | *(uint32_t *) (dst + off) = imm |
| 0x6a | sth [dst+off], imm | *(uint16_t *) (dst + off) = imm |
| 0x72 | stb [dst+off], imm | *(uint8_t *) (dst + off) = imm |
| 0x7a | stdw [dst+off], imm | *(uint64_t *) (dst + off) = imm |
| 0x63 | stxw [dst+off], src | *(uint32_t *) (dst + off) = src |
| 0x6b | stxh [dst+off], src | *(uint16_t *) (dst + off) = src |
| 0x73 | stxb [dst+off], src | *(uint8_t *) (dst + off) = src |
| 0x7b | stxdw [dst+off], src | *(uint64_t *) (dst + off) = src |
Branch Instructions
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x05 | ja +off | PC += off |
| 0x15 | jeq dst, imm, +off | PC += off if dst == imm |
| 0x1d | jeq dst, src, +off | PC += off if dst == src |
| 0x25 | jgt dst, imm, +off | PC += off if dst > imm |
| 0x2d | jgt dst, src, +off | PC += off if dst > src |
| 0x35 | jge dst, imm, +off | PC += off if dst >= imm |
| 0x3d | jge dst, src, +off | PC += off if dst >= src |
| 0xa5 | jlt dst, imm, +off | PC += off if dst < imm |
| 0xad | jlt dst, src, +off | PC += off if dst < src |
| 0xb5 | jle dst, imm, +off | PC += off if dst <= imm |
| 0xbd | jle dst, src, +off | PC += off if dst <= src |
| 0x45 | jset dst, imm, +off | PC += off if dst & imm |
| 0x4d | jset dst, src, +off | PC += off if dst & src |
| 0x55 | jne dst, imm, +off | PC += off if dst != imm |
| 0x5d | jne dst, src, +off | PC += off if dst != src |
| 0x65 | jsgt dst, imm, +off | PC += off if dst > imm (signed) |
| 0x6d | jsgt dst, src, +off | PC += off if dst > src (signed) |
| 0x75 | jsge dst, imm, +off | PC += off if dst >= imm (signed) |
| 0x7d | jsge dst, src, +off | PC += off if dst >= src (signed) |
| 0xc5 | jslt dst, imm, +off | PC += off if dst < imm (signed) |
| 0xcd | jslt dst, src, +off | PC += off if dst < src (signed) |
| 0xd5 | jsle dst, imm, +off | PC += off if dst <= imm (signed) |
| 0xdd | jsle dst, src, +off | PC += off if dst <= src (signed) |
| 0x85 | call imm | Function call |
| 0x95 | exit | return r0 |
示例1
1 |
|

raw eBPF map 使用
eBPF map 为以 key→value 映射格式存储数据的通用的数据存储结构,用于在不同程序之间共享数据,本节主要介绍 eBPF map 的基本用法
创建 eBPF map
可以通过 BPF_MAP_CREATE 命令创建一个新的 eBPF map,其会返回一个文件描述符作为该 map 的引用:
1 | static __always_inline int |
更新 eBPF map
可以通过 BPF_MAP_UPDATE 命令更新 map 中对应的 key→value 映射:
1 | static __always_inline int |
flags 应当为如下之一:
| flags | 描述 | 备注 |
|---|---|---|
| BPF_ANY | 有则更新,无则新建 | |
| BPF_NOEXIST | 仅在不存在时进行创建 | 若已有对应的 key 则返回 -EEXIST |
| BPF_EXIST | 仅在存在时进行更新 | 若无对应的 key 则返回 -ENOENT |
在创建新映射时若 map 中映射数量已经达到 max_entries 则会返回 E2BIG
在 eBPF map 中查找
我们可以通过 BPF_MAP_LOOKUP_ELEM 命令查找 map 中是否存在对应的 key,若是则内核会将 value 拷贝到用户空间指定的 value 缓冲区
1 | static __always_inline int |
遍历 eBPF map
BPF_MAP_GET_NEXT_KEY 是一个非常有意思的命令,其会在 map 中查找我们所传入的 key,并将该 key 的下一个 key 拷贝回用户空间,若不存在该 key 则会返回 0 并拷贝 map 中第一个 key 到用户空间,若该 key 为最后一个 key 则返回 -1 :
1 | static __always_inline int |
利用这个命令我们可以很方便地遍历一个 eBPF map:先传入一个不存在的 key 获取到 map 中的第一个 key,接下来再不断 BPF_MAP_GET_NEXT_KEY 直到返回 -1 即可
删除 eBPF map 数据
可以通过 BPF_MAP_DELETE_ELEM 命令删除 map 中已有的映射,若不存在则会返回 -EPERM :
1 | static __always_inline int |
销毁 eBPF map
在内核的 eBPF map 数据结构中会保存引用了该 map 的程序数量,若该 map 不再被任一程序引用则会自动释放,因此并不需要主动去销毁一个 eBPF map
示例2
1 |
|

拓展
在很多情况下,eBPF 并不直接使用,而是通过Cilium 、bcc 或bpftrace 等项目间接使用,这些项目在 eBPF 之上提供了抽象,不需要直接编写程序,而是提供指定基于意图的定义的能力,然后用 eBPF 实现。

如果不存在更高级别的抽象,则需要直接编写程序。Linux 内核希望 eBPF 程序以字节码的形式加载。虽然当然可以直接编写字节码,但更常见的开发实践是利用LLVM 等编译器套件将伪 C 代码编译为 eBPF 字节码。
Loder & Verifier architecture
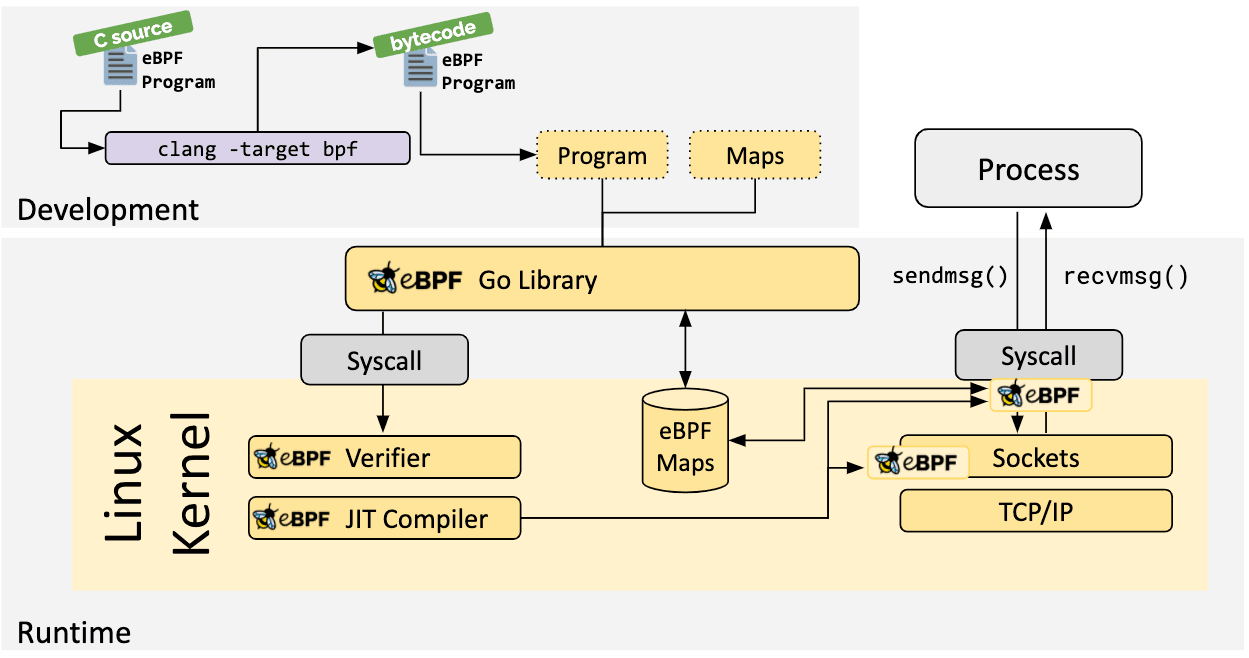
上图展示了一个 ebpf 程序从加载到验证结束经过 JIT 编译,从而在内核中发挥作用。
eBPF verifier
eBPF 程序的安全是通过两个步骤来保证的:
- 首先做一次 DAG 检查,确保没有循环,并执行其他 CFG validation。特别地,这会检查程序中是否有 无法执行到的指令(unreachable instructions,虽然 cBPF checker 是允许的)。
- 第二步是从程序的第一条指令开始,遍历所有的可能路径。这一步会模拟执行每一条指令,在过程中观察寄存器和栈的状态变化。
Verifier 的功能如下
1. 模拟执行
- 程序开始时,R1 中存放的是上下文指针(
ctx),类型是PTR_TO_CTX。- 接下来,如果校验器看到 R2=R1,那 R2 的类型也变成了 PTR_TO_CTX,并且接下来就能用在表达式的右侧。
- 如果 R1=PTR_TO_CTX 接下来的指令是 R2=R1+R1,那 R2=SCALAR_VALUE, 因为两个合法指针相加,得到的是一个非法指针。(在 “secure” 模式下, 校验器会拒绝任何类型的指针运算,以确保内核地址不会泄露给 unprivileged users)。
- 从来没有写入过数据的寄存器是不可读的,例如:
1 | bpf_mov R0 = R2 |
- 将会被拒绝,因为程序开始之后,R2 还没有初始化过。
- 内核函数执行完成后,R1-R5 将被重置为不可读状态,R0 保存函数的返回值。
- 由于 R6-R9 是被调用方(callee)保存的,因此它们的状态在函数调用结束之后还是有效的。
1 | bpf_mov R6 = 1 |
以上程序是合法的。如果换成了 R0 = R1,就会被拒绝,测试如下(将示例1中的命令简单修改)
1 | struct bpf_insn test_bpf_prog[] = { |
上面的命令中我们直接使用未初始化的 REG_0 赋值给 REG_1 是错误的

R0 !read_ok 表示验证器认为寄存器R0的值尚未初始化或不能安全读取。这通常发生在程序试图读取未正确初始化的寄存器时。
注意事项:从上图可以看到程序开始时,R1 类型是 PTR_TO_CTX(指向通用类型 struct bpf_context 的指针)
2. load/store 指令检查
load/store 指令只有当寄存器类型合法时才能执行,这里的类型包括 PTR_TO_CTX、PTR_TO_MAP、PTR_TO_STACK。会对它们做边界和对齐检查。例如:
1 | bpf_mov R1 = 1 |
将会被拒,因为执行到第三行时,R1 并不是一个合法的指针类型。
3. 定制化校验器,限制程序只能访问 ctx 特定字段
程序开始时,R1 类型是 PTR_TO_CTX(指向通用类型 struct bpf_context 的指针)。 可以通过 callback 定制化校验器,指定 size 和对齐,来 限制 eBPF 程序只能访问 ctx 的特定字段。 例如,下面的指令:
1 | bpf_ld R0 = *(u32 *)(R6 + 8) |
- 如果 R6=
PTR_TO_CTX,通过is_valid_access()callback,校验器就能知道从 offset 8 处读取 4 个字节的操作是合法的,否则,校验器就会拒绝这个程序。 - 如果 R6=
PTR_TO_STACK,那访问就应该是对齐的,而且在栈空间范围内,即[-MAX_BPF_STACK, 0)。在这里例子中 offset 是 8,因此校验会失败,因为超出 栈空间边界。
4. 读取栈空间
只有程序向栈空间写入数据后,校验器才允许它从中读取数据。cBPF 通过 M[0-15] memory slots 执行类似的检查,例如
1 | bpf_ld R0 = *(u32 *)(R10 - 4) |
是非法程序。因为虽然 R10 是只读寄存器,类型 PTR_TO_STACK 也是合法的,并且 R10 - 4 也在栈边界内,但在这次读取操作之前,并没有往这个位置写入数据。
5. 其他
指针寄存器(pointer register)spill/fill 操作也会被跟踪,因为 对一些程序来说,四个 (R6-R9) callee saved registers 显然是不够的。
可通过
bpf_verifier_ops->get_func_proto()来定制允许执行哪些函数。 eBPF 校验器会检查寄存器与参数限制是否匹配。调用结束之后,R0 用来存放函数返回值。函数调用是扩展 eBPF 程序功能的主要机制,但每种类型的 BPF 程 序能用到的函数是不同的,例如 socket filters 和 tracing 程序。
如果一个函数设计成对 eBPF 可见的,那必须从安全的角度对这个函数进行考量。校验 器会保证调用该函数时,参数都是合法的。
cBPF 中, seccomp 的安全限制与 socket filter 是不同的,它依赖两个级联的校验器:
- 首先执行 cBPF verifier,
- 然后再执行 seccomp verifier
而在 eBPF 中,所有场景都共用一个(可配置的)校验器。
更多关于 eBPF 校验器的信息,可参考 kernel/bpf/verifier.c 。
寄存器值跟踪(register value tracking)
为保证 eBPF 程序的安全,校验器必须跟踪每个寄存器和栈上每个槽位 (stack slot)值的范围。这是通过 struct bpf_reg_state 实现的,定义在 include/linux/bpf_verifier.h , 它统一了对标量和指针类型的跟踪(scalar and pointer values)。
每个寄存器状态都有一个类型,
NOT_INIT:该寄存器还未写入数据SCALAR_VALUE:标量值,不可作为指针- 指针类型
9 种指针类型
依据它们指向的数据结构类型,又可以分为:
PTR_TO_CTX:指向 bpf_context 的指针。CONST_PTR_TO_MAP:指向 struct bpf_map 的指针。 是常量(const),因为不允许对这种类型指针进行算术操作。PTR_TO_MAP_VALUE:指向 bpf map 元素的指针。PTR_TO_MAP_VALUE_OR_NULL:指向 bpf map 元素的指针,可为 NULL。 访问 map 的操作会返回这种类型的指针。禁止算术操作。PTR_TO_STACK:帧指针(Frame pointer)。PTR_TO_PACKET:指向 skb->data 的指针。PTR_TO_PACKET_END:指向 skb->data + headlen 的指针。禁止算术操作。PTR_TO_SOCKET:指向 struct bpf_sock_ops 的指针,内部有引用计数。PTR_TO_SOCKET_OR_NULL:指向 struct bpf_sock_ops 的指针,或 NULL。socket lookup 操作会返回这种类型。有引用计数, 因此程序在执行结束时,必须通过 socket release 函数释放引用。禁止算术操作。
这些指针都称为 base 指针。
1. 指针偏移(offset)触发寄存器状态更新
实际上,很多有用的指针都是 base 指针加一个 offset(指针算术运算的结果), 这是通过两方面来个跟踪的:
- ‘fixed offset’(固定偏移):offset 是个常量(例如,立即数)。
- ‘variable offset’(可变偏移):offset 是个变量。这种类型还用在 SCALAR_VALUE 跟踪中,来跟踪寄存器值的可能范围。
校验器对可变 offset 的支持包括:
- 无符号类型:最小和最大值;
- 有符号类型:最小和最大值;
- 关于每个 bit 的支持,以 ‘tnum’ 的格式: 一个 u64 ‘mask’ 加一个 u64 ‘value’。
重要总结:1s in the mask represent bits whose value is unknown; 1s in the value represent bits known to be 1. Bits known to be 0 have 0 in both mask and value; no bit should ever be 1 in both。 例如,如果从内存加载一个字节到寄存器,那该寄存器的前 56bit 已知是全零,而后 8bit 是未知的 —— 表示为
tnum (0x0; 0xff)。如果我们将这个值与 0x40 进行 OR 操作,就得到(0x40; 0xbf);如果加 1 就得到(0x0; 0x1ff),因为可能的进位操作。
2. 条件分支触发寄存器状态更新
除了算术运算之外,条件分支也能更新寄存器状态。例如,如果判断一个 SCALAR_VALUE 大于 8,那
- 在 true 分支,这个变量的最小值
umin_value(unsigned minimum value)就是 9; - 在 false 分支,它的最大值就是 umax_value of 8。
3. 有符号比较触发寄存器状态更新
有符号比较(BPF_JSGT or BPF_JSGE)也会相应更新有符号变量的最大最小值。
有符合和无符号边界的信息可以结合起来;例如如果一个值先判断小于无 符号 8,后判断大于有符合 4,校验器就会得出结论这个值大于无符号 4,小于有符号 8 ,因为这个边界不会跨正负边界。
4. struct bpf_reg_state 的 id 字段
struct bpf_reg_state 结构体有一个 id 字段,
1 | // include/linux/bpf_verifier.h |
如注释所述,该字段针对不同指针类型有不同用途,下面分别解释。
PTR_TO_PACKET
id 字段对共享同一 variable offset 的多个 PTR_TO_PACKET 指针 都是可见的,这对skb 数据的范围检查非常重要。举个例子:
1 | 1: A = skb->data // A 是指向包数据的指针 |
在这个程序中,寄存器 A 和 B 将将共享同一个 id,
- A 已经从最初地址向前移动了 4 字节(有一个固定偏移 +4),
- 如果这个边界通过校验了,也就是确认小于
PTR_TO_PACKET_END,那现在 寄存器 B 将有一个范围至少为 4 字节的可安全访问范围(这里我也没有理解,明明加了var2,为什么说是至少4字节的可安全访问范围)。
PTR_TO_MAP_VALUE
与上面的用途类似,具体来说:
- 这一字段对共享同一基础指针的多个 PTR_TO_MAP_VALUE 指针可见;
- 这些指针中,只要一个指针经验证是非空的,就认为其他指针(副本)都是非空的(因此减少重复验证开销);
另外,与 range-checking 类似,跟踪的信息(the tracked information)还用于确保指针访问的正确对齐。 例如,在大部分系统上,packet 指针都 4 字节对齐之后再加 2 字节。如果一个程序将这个指针加 14(跳过 Ethernet header)然后读取 IHL,并将指针再加上 IHL * 4,最终的指针将有一个 4n + 2 的 variable offset,因此,加 2 (NET_IP_ALIGN) gives a 4-byte alignment,因此通过这个指针进行 word-sized accesses 是安全的。
PTR_TO_SOCKET
与上面用途类似,只要一个指针验证是非空的,其他共享同一 id 的 PTR_TO_SOCKET 指针就都是非空的;此外, 还负责跟踪指针的引用(reference tracking for the pointer)。
PTR_TO_SOCKET 隐式地表示对一个 struct sock 的引用。为确保引用没有泄露,需要强制对引用进行非空(检查), 如果非空(non-NULL),将合法引用传给 socket release 函数。
直接数据包访问(direct packet access)
对于 cls_bpf 和 act_bpf eBPF 程序,校验器允许直接通过 skb->data 和 skb->data_end 指针访问包数据。
简单例子
1 | 1: r4 = *(u32 *)(r1 +80) /* load skb->data_end */ |
上面从包数据中加载 2 字节的操作是安全的,因为程序编写者在第五行主动检查了数据边界: if (skb->data + 14 > skb->data_end) goto err,这意味着能执行到第 6 行时(fall-through case), R3(skb->data)至少有 14 字节的直接可访问数据,因此 **校验器将其标记为 R3=pkt(id=0,off=0,r=14)**:
id=0表示没有额外的变量加到这个寄存器上;off=0表示没有额外的常量 offset;r=14表示安全访问的范围,即[R3, R3+14)指向的字节范围都是 OK 的。
这里注意 **R5 被标记为 R5=pkt(id=0,off=14,r=14)**,
- 它也指向包数据,但常量 14 加到了寄存器,因为它执行的是
skb->data + 14, - 因此可访问的范围是
[R5, R5 + 14 - 14),也就是 0 个字节。
复杂例子
下面是个更复杂一些的例子:
1 | R0=inv1 R1=ctx R3=pkt(id=0,off=0,r=14) R4=pkt_end R5=pkt(id=0,off=14,r=14) R10=fp |
校验器标记信息解读
第 18 行之后,寄存器 R3 的状态是 R3=pkt(id=2,off=0,r=8),
id=2表示之前已经跟踪到两个 r3 += rX 指令,因此 r3 指向某个包内的某个 offset,由于程序员在 18 行已经做了if (r3 + 8 > r1) goto err检查,因此安全范围是[R3, R3 + 8)。- 校验器只允许对 packet 寄存器执行 add/sub 操作。其他操作会将寄存器状态设为 SCALAR_VALUE,这个状态是不允许执行 direct packet access 的。
操作 r3 += rX 可能会溢出,变得比起始地址 skb->data 还小,校验器必须要能检查出这种情况。 因此当它看到 r3 += rX 指令并且 rX 比 16bit 值还大时,接下来的任何将 r3 与 skb->data_end 对比的操作都不会返回范围信息,因此尝试通过 这个指针读取数据的操作都会收到 invalid access to packet 错误。 例如,
r4 = *(u8 *)(r3 +12)之后,r4 的状态是R4=inv(id=0,umax_value=255,var_off=(0x0; 0xff)),意思是 寄存器的 upper 56 bits 肯定是 0,但对于低 8bit 信息一无所知。 在执行完r4 *= 14之后,状态变成R4=inv(id=0,umax_value=3570,var_off=(0x0; 0xfffe)),因为一个 8bit 值乘以 14 之后, 高 52bit 还是 0,此外最低 bit 位为 0,因为 14 是偶数。- 类似地,
r2 >>= 48使得R2=inv(id=0,umax_value=65535,var_off=(0x0; 0xffff)),因为移位是无符号扩展。 这个逻辑在函数adjust_reg_min_max_vals()中实现,它又会调用adjust_ptr_min_max_vals()adjust_scalar_min_max_vals()
Pruning(剪枝)
校验器实际上并不会模拟执行程序的每一条可能路径。
对于每个新条件分支:校验器首先会查看它自己当前已经跟踪的所有状态。如果这些状态已经覆盖到这个新分支,该分支就会被剪掉(pruned)—— 也就是说之前的状态已经被接受 (previous state was accepted)能证明当前状态也是合法的。
举个例子:
- 当前的状态记录中,r1 是一个 packet-pointer
- 下一条指令中,r1 仍然是 packet-pointer with a range as long or longer and at least as strict an alignment,那 r1 就是安全的。
类似的,如果 r2 之前是 NOT_INIT,那就说明之前任何代码路径都没有用到这个寄存器 ,因此 r2 中的任何值(包括另一个 NOT_INIT)都是安全的。
实现在 regsafe() 函数。
Pruning 过程不仅会看寄存器,还会看栈(及栈上的 spilled registers)。 只有证明二者都安全时,这个分支才会被 prune。这个过程实现在 states_equal() 函数。
这一部分还未理解,什么叫这些状态已经覆盖到这个新分支
helper function
eBPF 程序无法调用任意内核函数,这样做会将 eBPF 程序绑定到特定内核版本,并使程序的兼容性变得复杂。相反,eBPF 程序可以调用辅助函数,这是内核提供的一个众所周知且稳定的 API。

辅助函数一直再发展,下面是一些辅助函数的例子:
- Generate random numbers
- Get current time & date
- eBPF map access
- Get process/cgroup context
- Manipulate network packets and forwarding logic
理解 eBPF 校验器提示信息
提供几个不合法的 eBPF 程序及相应校验器报错的例子。
1. 程序包含无法执行到的指令
1 | static struct bpf_insn prog[] = { |
Error:
1 | unreachable insn 1 |
2. 程序读取未初始化的寄存器
1 | BPF_MOV64_REG(BPF_REG_0, BPF_REG_2), |
Error:
1 | 0: (bf) r0 = r2 |
3. 程序退出前未设置 R0 寄存器
1 | BPF_MOV64_REG(BPF_REG_2, BPF_REG_1), |
Error:
1 | 0: (bf) r2 = r1 |
4. 程序访问超出栈空间
1 | BPF_ST_MEM(BPF_DW, BPF_REG_10, 8, 0), |
Error:
1 | 0: (7a) *(u64 *)(r10 +8) = 0 |
5. 未初始化栈内元素,就传递该栈地址
1 | BPF_MOV64_REG(BPF_REG_2, BPF_REG_10), |
Error::
1 | 0: (bf) r2 = r10 |
6. 程序执行 map_lookup_elem() 传递了非法的 map_fd
1 | BPF_ST_MEM(BPF_DW, BPF_REG_10, -8, 0), |
Error:
1 | 0: (7a) *(u64 *)(r10 -8) = 0 |
7. 程序未检查 map_lookup_elem() 的返回值是否为空就开始使用
1 | BPF_ST_MEM(BPF_DW, BPF_REG_10, -8, 0), |
Error:
1 | 0: (7a) *(u64 *)(r10 -8) = 0 |
8. 程序访问 map 内容时使用了错误的字节对齐
程序虽然检查了 map_lookup_elem() 返回值是否为 NULL,但接下来使用了错误的对齐:
1 | BPF_ST_MEM(BPF_DW, BPF_REG_10, -8, 0), |
Error:
1 | 0: (7a) *(u64 *)(r10 -8) = 0 |
9. 程序在 fallthrough 分支中使用了错误的字节对齐访问 map 数据
程序检查了 map_lookup_elem() 返回值是否为 NULL,在 if 分支中使用了正确的字节对齐, 但在 fallthrough 分支中使用了错误的对齐:
1 | BPF_ST_MEM(BPF_DW, BPF_REG_10, -8, 0), |
Error:
1 | 0: (7a) *(u64 *)(r10 -8) = 0 |
10. 程序执行 sk_lookup_tcp(),未检查返回值就直接将其置 NULL
1 | BPF_MOV64_IMM(BPF_REG_2, 0), |
Error:
1 | 0: (b7) r2 = 0 |
这里的信息提示是 socket reference 未释放,说明 sk_lookup_tcp() 返回的是一个非空指针, 直接置空导致这个指针再也无法被解引用。
11. 程序执行 sk_lookup_tcp() 但未检查返回值是否为空
1 | BPF_MOV64_IMM(BPF_REG_2, 0), |
Error:
1 | 0: (b7) r2 = 0 |
这里的信息提示是 socket reference 未释放,说明 sk_lookup_tcp() 返回的是一个非空指针, 直接置空导致这个指针再也无法被解引用。
总结
Pruning 这一部分暂未理解
- Title: ebpf Basic Knowledge
- Author: henry
- Created at : 2025-02-10 21:26:52
- Updated at : 2025-02-25 17:49:32
- Link: https://henrymartin262.github.io/2025/02/10/ebpf_study/
- License: This work is licensed under CC BY-NC-SA 4.0.