CVE-2022-20186 mali gpu 漏洞利用

CVE-2022-20186 mali gpu 漏洞利用
Mali GPU架构的命名灵感源自北欧神话,从 Utgard、Midgard、Bifrost 到最新的 Valhall。大多数现代安卓手机采用的是Bifrost或Valhall 架构,它们的内核驱动程序共享了大量代码。由于这些新架构在很大程度上基于 Midgard 架构,因此在 Bifrost 或 Valhall 驱动程序中有时会存在以“MIDGARD”为前缀的宏(例如MIDGARD_MMU_LEVEL)。
Memory management in the Mali kernel driver
GPU与用户空间进程之间共享内存有多种方式,但在这里仅讨论由驱动程序管理共享内存的情况。在这种情况下,用户首先调用KBASE_IOCTL_MEM_ALLOC ioctl从kbase_context中分配页面。这些页面是从kbase_context中的每个上下文内存池 mem_pools中分配的,并且不会立即映射到GPU或用户空间。ioctl向用户返回一个cookie,该cookie随后被用作mmap设备文件的偏移量offset,并将这些页面映射到GPU和用户空间,当使用munmap取消内存映射时,支持页面会被回收回mem_pools。
kbase_context为用户空间应用程序与GPU交互定义了一个执行环境。每个与GPU交互的设备文件都有一个独立的kbase_context。除此之外,kbase_context还定义了它自己的GPU地址空间,并管理用户空间和GPU的内存共享
1 | struct kbase_va_region *kbase_mem_alloc(struct kbase_context *kctx, |
该函数会创建一个 kbase_ba_region 对象去存储相关内存地址信息,同时该函数也会通过调用 kbase_alloc_phy_pages 从 kbase_context的内存池 mem_pool中分配backing pages(可以理解我们申请的堆块)。
当从64位进程调用时,所创建的区域会存储在kbase_context的pending_regions中,而不是立即进行映射。
1 | if (*flags & BASE_MEM_SAME_VA) { |
上述代码中的 cookie 值将会返回给用户,该值将可以被用作 mmap 调用的 offset 参数,从而映射申请的内存空间给用户。
Mapping pages to user space
了解在调用mmap映射该区域时虚拟地址是如何分配的这一点非常重要,这里简要介绍用户空间映射,当调用mmap时,会使用 kbase_context_get_unmapped_area 来找到一个空闲区域进行映射:
1 | unsigned long kbase_context_get_unmapped_area(struct kbase_context *const kctx, |
该调用不允许使用 MAP_FIXED 标志将内存映射到固定的虚拟地址。相反,使用 kbase_unmapped_area_topdown 来查找一个足够大以容纳所请求内存的空闲区域,并返回其地址,顾名思义,kbase_unmapped_area_topdown 返回的是可用的最高地址。
然后,将映射的地址存储为 kbase_va_region 中的 start_pfn 字段,从一定程度上这意味着连续映射区域的相对地址是可预测的。
1 | int fd = open("/dev/mali0", O_RDWR); |
这里 region2 的虚拟地址将会是 region1-0x1000 。
Mapping pages to the GPU
每个kbase_context维护着自己的GPU地址空间,并管理自己的GPU页表。同时,每个kbase_context维护着一个四级页表,用于将GPU地址转换为支撑的物理页。它有一个mmut字段,用于存储作为pgd字段的顶级页表全局目录(PGD)。mmut->pgd被解释为512个元素的int64_t数组的页(512*8 = 4096B = 1KB),其条目指向存储下一级PGD的页帧,直到到达最底层,页表条目(PTE)存储backing pages(以及页面权限)。
由于大多数地址未被访问,PGD 和 PTE 只有在需要时才会被创建:
1 | static int mmu_get_next_pgd(struct kbase_device *kbdev, |
当一个访问需要特定的页全局目录(Page Global Directory,简称PGD)时,它会从上一级PGD(上述中的1)中查找条目。由于一个PGD的所有条目都被初始化为一个表示条目无效的特定值(magic value),如果之前从未访问过该条目,那么1将返回一个空指针(NULL pointer),这将导致为 target_pgd(上述中的2)分配内存。然后,将 target_pgd的地址作为条目添加到之前的PGD中(上述中的3)。
注意事项
backing target PGD的页帧是通过全局 kbase_device kbdev的mem_pools分配的,而 kbdev 是一个所有上下文共享的全局内存池。
当映射内存给GPU时,kbase_gpu_mmap 将会调用kbase_mmu_insert_pages 添加 backing pages到 GPU 页表。
1 | int kbase_gpu_mmap(struct kbase_context *kctx, struct kbase_va_region *reg, u64 addr, size_t nr_pages, size_t align) |
这将在由reg->start_pfn指定的地址处插入backing pages,该地址也是用户空间中内存区域的地址。
Memory alias
KBASE_IOCTL_MEM_ALIAS 允许多个内存区域共享相同的 backing pages,在 kbase_mem_alias 中实现,接受一个 stride 参数,以及一个 base_mem_aliasing_info 数组,用于指定为别名区域提供支持的内存区域。
1 | union kbase_ioctl_mem_alias alias = {0}; |
在上述,通过将这些区域 region1 和 region2 (两者都是已经映射到 GPU 的区域) 的地址作为 base_mem_aliasing_info::handle::basep::handle 传递,创建了一个由 region1 和 region2 支持的别名区域。
stride 参数表示这两个别名区域之间的间隔(以页为单位),nents 是 backing regions 的数量(注意这里不是backing pages),所创建的结果区域的大小为 stride * nents 页,参照下图:
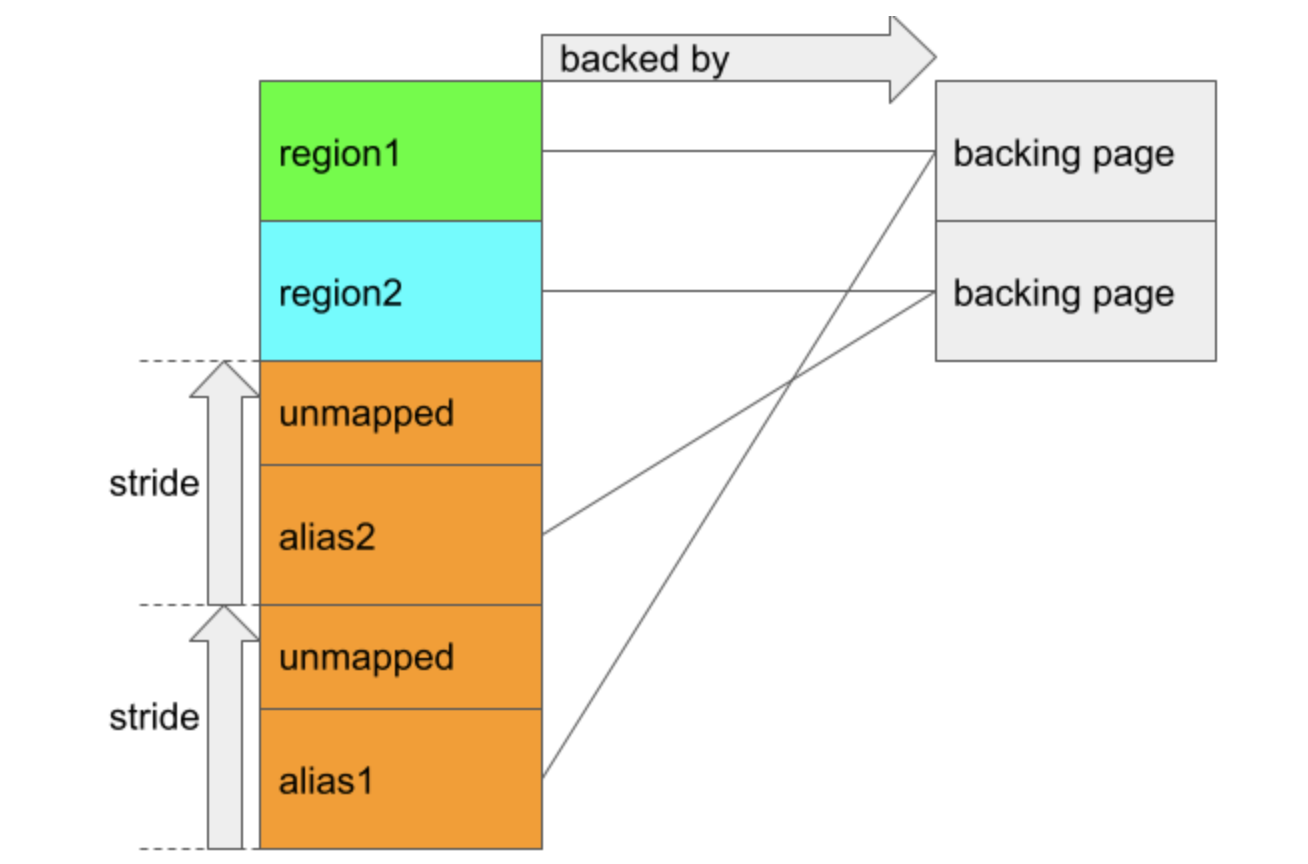
橙色区域表示整个别名区域,该区域包含2 * 4 = 8页。实际上,只有6页被映射,并且分别由region1和region2的 backing pages 支持。如果别名区域的起始地址是alias_start,那么alias_start到alias_start + 0x3000(三页)之间的地址与region1存在别名关系,而region2与alias_start + stride * 0x1000到alias_start + (stride + 3) * 0x1000之间的地址存在别名关系。
这导致别名区域中有一些间隙未被映射。这可以从kbase_gpu_mmap中处理KBASE_MEM_TYPE_ALIAS内存区域的方式中看出:
1 | if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) { |
从上面的代码可以看到reg->start_pfn + (i * stride) 是对应 region 开始的别名内存区域开始映射的起始位置。
Vulnerability
根据前面的内容,可以知道别名区域alias region的大小为stride*nents,代码如下:
1 | u64 kbase_mem_alias(struct kbase_context *kctx, u64 *flags, u64 stride, |
虽然存在 (nents * stride) > (U64_MAX / PAGE_SIZE) 检查,但是并没有做溢出检查,因此这里存在整数溢出,设想下面一个场景:
首先,分配三个0x1000 * 3大小的区域(region1、region2和region3)分配给GPU并建立映射,并将它们的起始地址分别标记为region1_start、region2_start和region3_start。
然后,创建一个别名区域,其步长(stride)为2**63 + 1,nents(元素数量)为2,并建立映射。由于整数溢出,别名区域的大小变为2页,特别是,别名区域的起始地址 alias_start = region3_start - 0x2000,其中0x2000是别名区域的大小,当别名区域映射到GPU时,kbase_gpu_mmap将在alias_start处插入三个页面。
1 | if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) { |
由于 region1 的 backing pages 大小为 0x3000,而对应region3_start位于alias_start + 0x2000处,因此会导致region_1中一个page大小的页面被映射到 region3 的区域当中,具体情况如下:
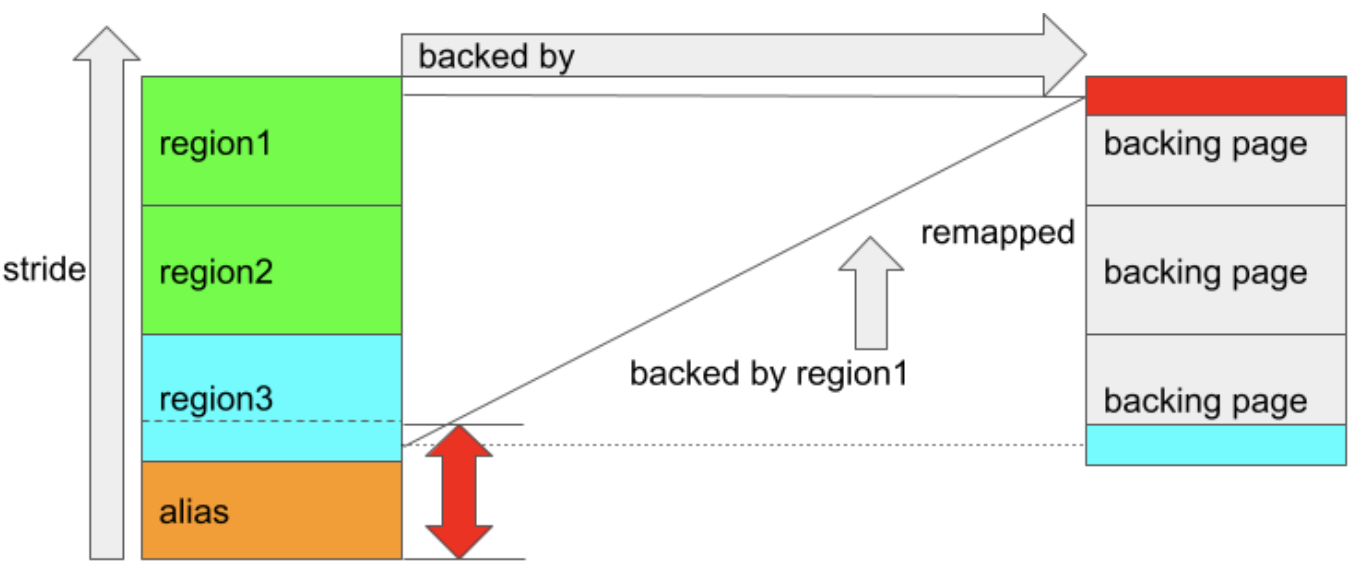
图中右侧的红色矩形表示在重新映射发生后,同时可以被 region1_start + 0x2000 和 region3_start 使用的一个页面。由于标记为红色的backing page同时还由alias region所拥有,即如果这两个区域(region_start & alias)都取消映射,则该页面将被释放并回收到内存池中。
如果在这时候取消这两个区域的映射(对应的页面会被释放到内存池memory region当中),意味着 GPU 仍然可以通过访问 region3_start处的地址来访问这个已被释放的页面,从而顺利完成 UAF 的效果。
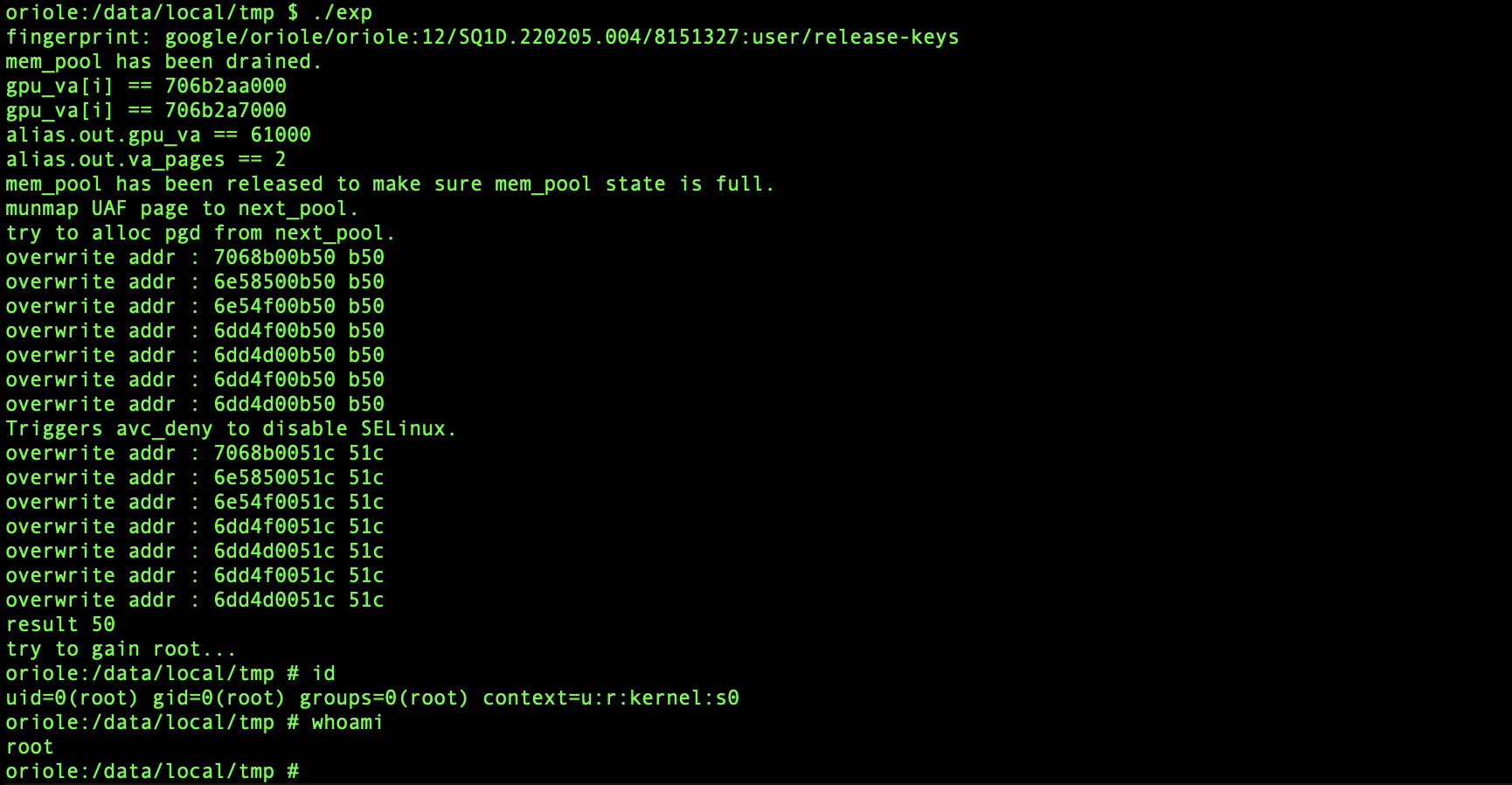
剩下的方法与 GHSL-2023-005 中所采用的方法一致,通过堆风水将 backing page 释放到 next_pool 中,然后通过 PGD 分配也会从该内存池中获取页面,从而相当于我们可以通过控制该 UAF 页面来实现对,PGD 页表的读写,从而实现任意物理内存读写这一强大原语。
explain exp
write_adrp
1 | uint32_t write_adrp(int rd, uint64_t pc, uint64_t label) { |
这里需要先解释一下 adrp 指令,ADRP (Add Relative to Instruction Pointer) 是 ARM64 架构中的一条指令,用于将当前指令的程序计数器 (PC) 值与一个相对偏移量相加,得到一个目标地址,并将这个地 址存储到一个寄存器中。以下是 ADRP 指令的构成:

1 | uint32_t init_adpr = write_adrp(0, read_enforce, init_cred); |
这里需要说明的是ARMv8采用的是定长指令集,这里是32位,write_adrp负责生成一条adrp指令,剩下两条指令解释如下:
ADRP 和 ADD 的组合原理
• ADRP(Address of Page Relocatable Page):
• 将页对齐的地址加载到寄存器中,即目标地址的高位部分。
• 它只计算到 4KB 页的基地址,因此低 12 位总是被截断为 0。
• ADD(加法指令):
• 用于修正 ADRP 产生的基地址,将目标地址的低 12 位(偏移)添加到寄存器中。
由于 ADRP 只能处理 4KB 页对齐的地址,但实际的目标地址可能位于某个页内的特定偏移位置。例如:
• 假设 label 地址是 0x12345678。
• ADRP 只能加载 0x12345000(页对齐的高地址)。
• ADD 则需要将偏移 0x678 添加到 ADRP 结果中
map_gpu
1 | void* map_gpu(int mali_fd, unsigned int pages, bool read_only, int group) { |
map_gpu中的group指定了申请的内容属于哪个组,在这个例子中,我们在 write_to 的时候设置的group为0,而触发漏洞的group设置为1,因此可以将这两块内存隔离,而不受影响。
write_func
1 | uint64_t set_addr_lv3(uint64_t addr) { |
上面 for 循环中的 write_to 用于覆盖页表项,注意这里的OVERWRITE_INDEX 的值为 0x100 = 256,此时可以理解为gpu_va[1] + i * 0x1000已经指向了一张 level 3 pgd 页表,我们修改了第 256 个页表项的内容(位于0x100*8 = 0x800处),修改的内容为avc_deny这个函数物理地址所对应的页帧号,这一操作通过(((avc_deny + KERNEL_BASE) >> PAGE_SHIFT) << PAGE_SHIFT)| 0x443 完成,其中 0x443 是对应页表项低 12位的属性字段的值(具体可参考armV8 文档)用来保证页表项有效且可对页面进行读写。
在修改了页表项之后,此时 reserved[i]中的某一页已经指向了对应的avc_deny函数所在的页面,一种暴力的方法是我们直接对遍历每一个reserved[i] + j * 0x1000 修改对应的avc_deny函数偏移处的代码,但实际上完全不用这么做,armV8 采用的是三级页表,总共的有效地址位数为3 * 9 + 12 = 39,其中三级页表对应的索引为 addr[20:12],由于我们将 OVERWRITE_INDEX设置为了256,因此只要对应虚拟地址三级索引设置为0x100,我们就能够定位到所修改的 evil 页表项的位置,这也解释了set_addr_lv3中为什么有了这段代码 pfn &= ~ 0x1FFUL; pfn |= 0x100UL;,也就意味着仅仅需要关注reserved[i] + j*0x1000 虚拟地址中对应一级索引和二级索引不一样的地址就行。
作为验证可以把OVERWRITE_INDEX 设置为 255(0xff),然后在 set_addr_lv3 中对应的设置为pfn |= 0xffUL也能成功命中对应的页表项。
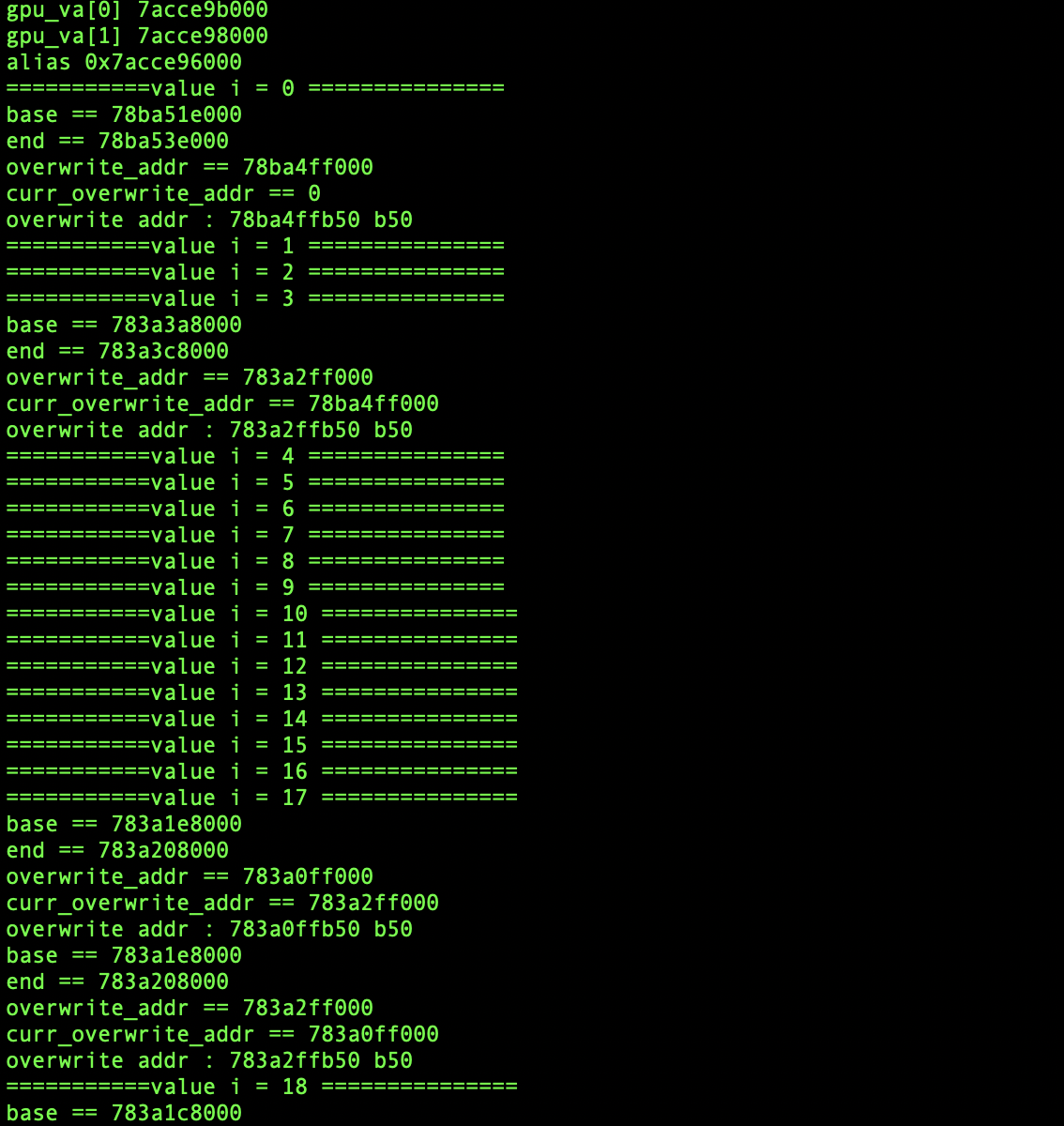
最终效果如下:
Final exp
1 |
|
Reference:
https://github.blog/security/vulnerability-research/corrupting-memory-without-memory-corruption/
- Title: CVE-2022-20186 mali gpu 漏洞利用
- Author: henry
- Created at : 2024-12-02 16:59:07
- Updated at : 2024-12-02 17:07:08
- Link: https://henrymartin262.github.io/2024/12/02/CVE-2022-20186/
- License: This work is licensed under CC BY-NC-SA 4.0.