看论文 Towards Understanding the Effectiveness of Large Language Models on Directed Test Input Generation

看论文 Towards Understanding the Effectiveness of Large Language Models on Directed Test Input Generation
主要研究的是大语言模型在生成定向输入测试集时的性能,还有和已有的约束求解器之间的比较。
1 Introduction
首先文章提出自动化测试对于程序的可靠性和安全性有着极为重要的作用。这些自动化测试技术包括 fuzzing,property-guided random testing,符号执行和 search-based evolutionary 技术,但这些都面临着一个相同的问题就是如何提高测试覆盖率(本文着重讨论的问题)。
之后文章引出约束求解器在某些方面的不足,如存在路径爆炸问题,还有就是在处理系统调用和网络通信方面存在的不足。这里作者举了一个例子

在上面这个例子中,为了执行到 target line,约束求解器很难有效完成这个工作,实际上只要输入一个完整有效的 linux 命令即可,但相反 LLM 却可以通过指定字符串 s 的内容,来轻松完成这个工作。但同时作者又通过另外一个例子来说明在有些情况下,LLM 不能完成的但是约束求解器可以完成。

在 Figure 2 中,需要设置一个 s[0] 使得最后能通过条件语句,进入到目标行,其实用过符号执行工具的小伙伴都知道,这一点约束求解器完全可以做到求解出具体的 s[0]。但同样的,LLM 却在完成这项任务时有些乏力。
通过这两个例子其实不难总结出,LLM 和 约束求解器各自的优势和劣势,在需要一些外部知识加持的上下文时(比如第一个例子,要给出一个有效的命令),LLM 是有优势的,但是在面对一些需要精确计算的案例时,约束求解器却展现出了其优势。这时候也就自然引出了一个想法,那么就是如果将这两者结合起来,是否能够让生成的输入集更强大(能够满足更高的覆盖率),事实上经过作者团队的测试,这样确实可以大大提高有效测试输入的生成。
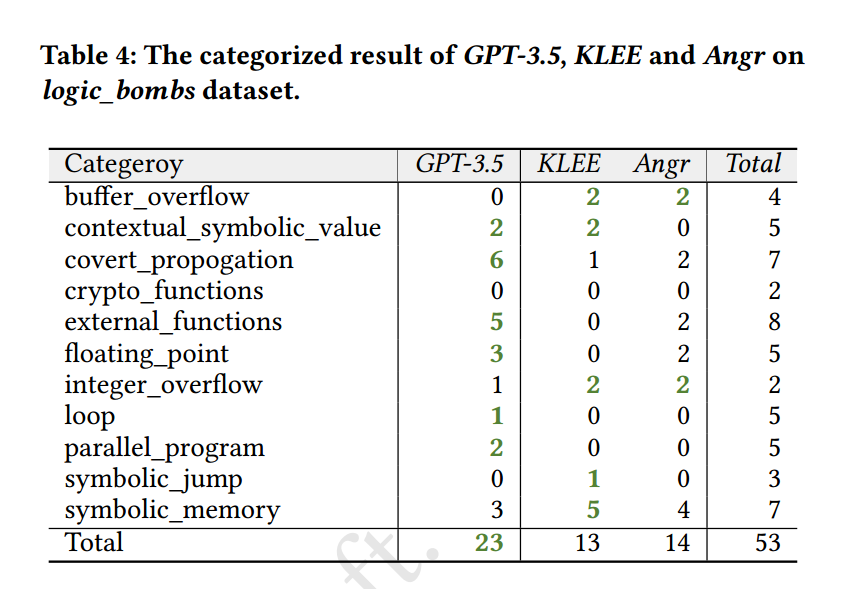
同时,作者为了更明显的比较 LLM 和约束求解器各自的优势和劣势,使用了两个测试集,一个是 logic_bombs,另外一个是由 HumanEval-X 转化的测试集 PathEval 。
文章主要贡献如下:
- Originality:系统研究 LLM 生成测试输入,并且与现有的约束求解器进行比较
- Findings:LLM 和约束求解器都有其各自的优点和缺点
- Perspective:基于上一步骤,将两者合并起来,并在生成测试输入上展现出不错的效果
- Open-Source:文章中的所有代码已开源,https://github.com/CGCL-codes/PathEval
2 Background and Motivation
定向测试输入(directed test input)生成的目标是生成基于给定目标的测试用例。在生成定向测试输入一般存在两种方法:
1. Constraint-based Approaches
基于约束生成测试输入是一种经典的方法,这种方法又可以划分为符号执行和动态符号执行,顾名思义这些工具是通过求解约束来探索程序中的执行路径。在灰盒模糊测试当中,一般会将那些难以覆盖的分支交给符号执行的这些工具以方便来达到更好的性能。
2. LLM-based Approaches
论文指出最近的研究表明LLM也可以用于测试输入的生成,从而让覆盖率提高,但是LLM存在的一个问题就是有时会存在错误的输出。同时LLM和约束求解器之间有效性也没有被深究过(本篇论文的重心)。
3 Experimental Setup
3.1 Research Questions
三个问题
- LLMs 在生成定向测试输入方面的表现如何
- LLMs 相比如传统的约束求解器,其性能如何
- 是否可以将 LLMs 融入到这些约束求解器中,以获得更好的性能
3.2 Benchmark Construction
这一部分论文主要指出已有的benchmark在测试文章中讨论的问题时存在的一些缺陷,目前的数据测试集有 logic_bomb 和 CGC,但这两个都有各自的缺点,logic_bomb 的样本数量太少(53个),不足以支持实验研究,而 CGC 的数据集是针对内存不安全语言(C\C++)生成的,因此其并不能反应真实的开发场景,以用来方便我们进行测试输入生成。CruxEval 是LLM代码推理、理解和执行的基准,CruxEval中的样本从函数的给定输出推断输入的形式构造,反之亦然,但是CruxEval 的数据集通常代码量都比较少,由于在真实环境中的情况都比较复杂,所以使用 CruxEval 中的数据作为测试集也是欠缺的。同时,从头构造一个测试数据集也是非常麻烦的。
因此,基于以上问题,论文中所采用的方法就是通过扩展已有的数据集来达成目的,这里选择的是 HumanEval 作为原始数据集,OpenAI引入的HumanEval是目前最著名的用于评估LLM在代码任务上的性能的基准,为了满足多语言这一特性,使用 HumanEval-X 作为原始数据集,将 HumanEval-X进行扩展后的数据集为 PathEval。

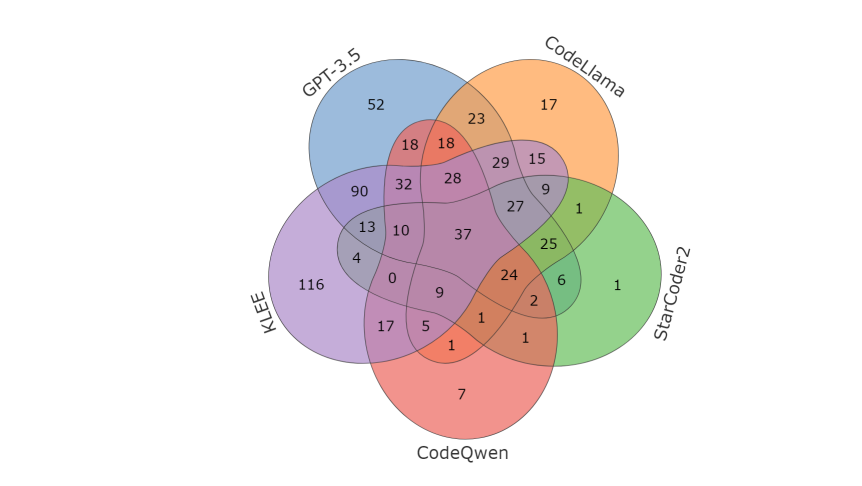
上图即为最终扩展后的测试集用例,分别对应三种语言,C++,python,java,总共大约有2000个左右的测试用例。
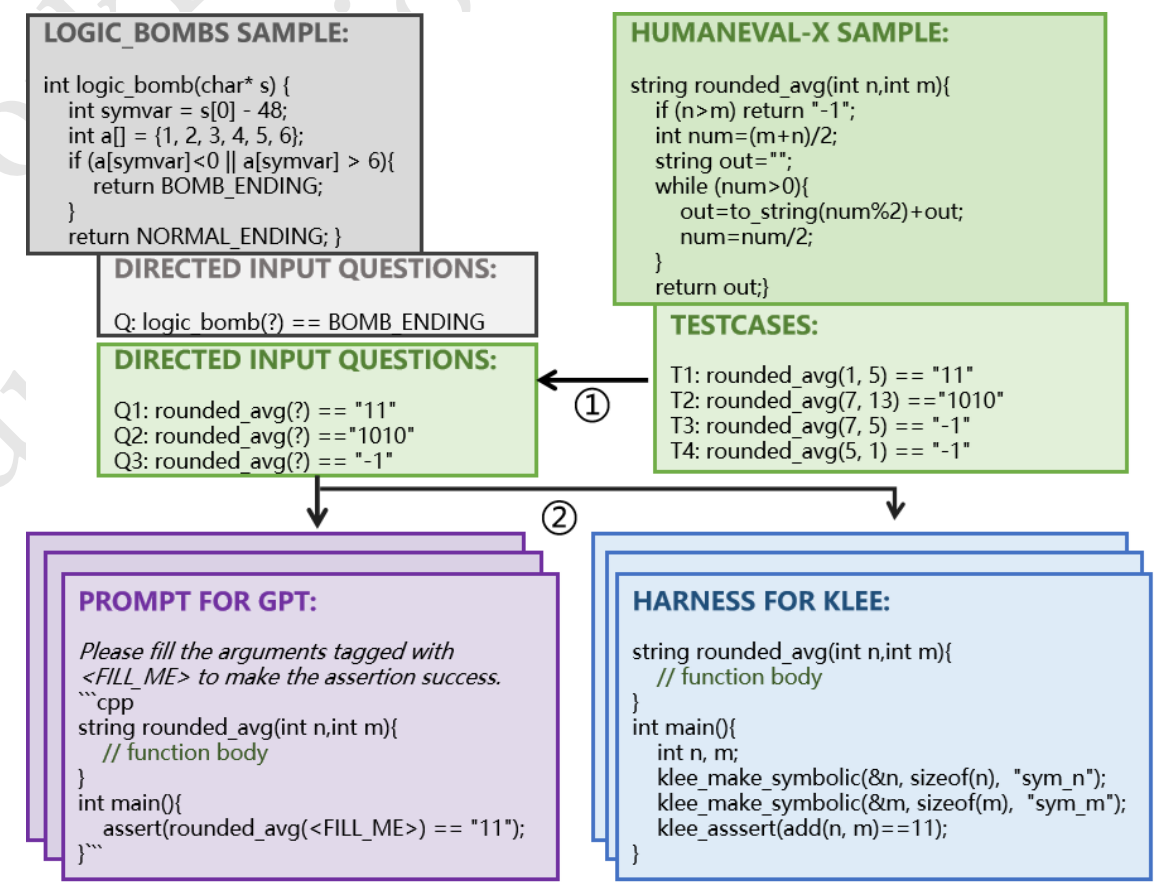
这里所采用的测试思路也是非常简单的,先通过正向输入来得到最终结果(绿色图部分给出了具体过程),如 T1:rounded_avg(1,5)=="11",这样就算是一个测试用例,在交由 LLM 进行求解时,则将对应 rounded_avg 中的参数进行替换,只给出结果,进行逆向求解,并且生成对应 prompt 交给 GPT 进行回答(紫色部分),同时上图也给出了使用 KLEE 进行测试时的方法(蓝色部分)。
这里为了显示表示出 LLMs 生成测试输入的性能,引入通过率(pass rate),简单来说就是通过测试的数量比上总共的测试数。
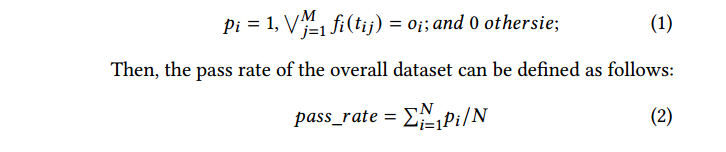
为了方便里面,稍微解释一下这个公式,M具体代表的是前面那张图里面的 testcases 的数目为 4(T1-T4),N指的是使用的 Sample 的数目,具体表现为就是前面表格里面生成的所有的数据集。需要注意的是第一个公式,当 M 个testcases中有至少一个通过时,则有
3.3 Studied LLMs and constraint-base tools
在与代码相关工作有关的LLMs中,有如下比较优秀的开源和闭源大模型,参考链接 :
- GPT3.5:已被用于一些前沿的工作,另外其花费也比 GPT4 少的多
- StarCoder2:用于代码生成,选择使用 7B(模型所使用的参数) 模型,15B在性能上显示出了一定的缺陷
- CodeLlama:有着比较好的性能,先进的填充能力
- CodeQwen:在 code-related tasks 排行榜中表现最好
同时,也有一些常用的符号执行工具:
- KLEE:支持C\C++的符号执行工具
- Angr:支持多架构,以及程序分析等,在逆向,CTF,二进制分析中使用广泛
- CrossHair:支持 python 的符号执行工具
- EvoSuite:支持 java 的符号执行工具
4 Evaluation Result
4.1 RQ1: Effectiveness of LLM
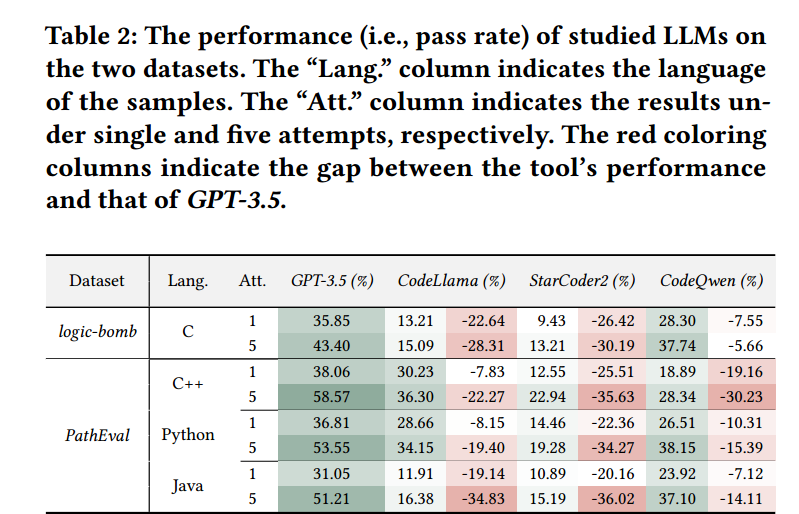
这张图其实反映了各个大模型在生成测试输入方面的性能表现,其中 lang 表示的是对应的编程语言,Att. 代表的是同一个样本所测试的次数,根据上图可以发现,连续测试5次的情况下的结果是远远好于只测试1次的情况(所以这也给了我们一些使用大模型的思路,就是多测试几次,说不定结果会更好一点)。同时也可以通过表格中的数据发现 GPT-3.5 的效果是远远好于其他 LLMs 的,再次展现了 GPT 的强大。
4.2 RQ2: Comparison with Traditional Tools
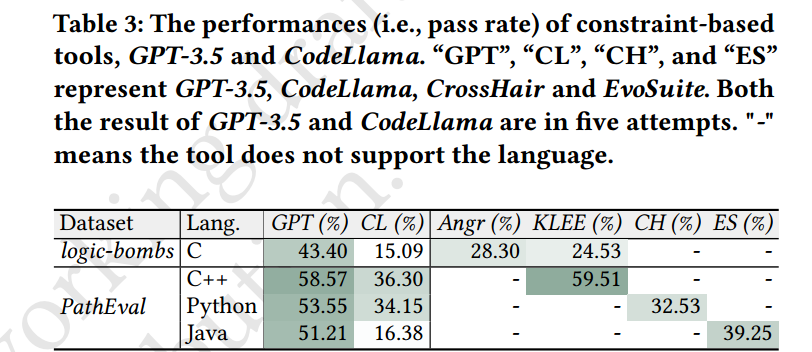
执行性能如上,可以从图很明显看出区别,这里不做过多说明。
GPT-3.5 和其他约束求解器在特定测试集上的比较

4.3 RQ3: Integrating LLMs with Traditional Tools for Better Performance
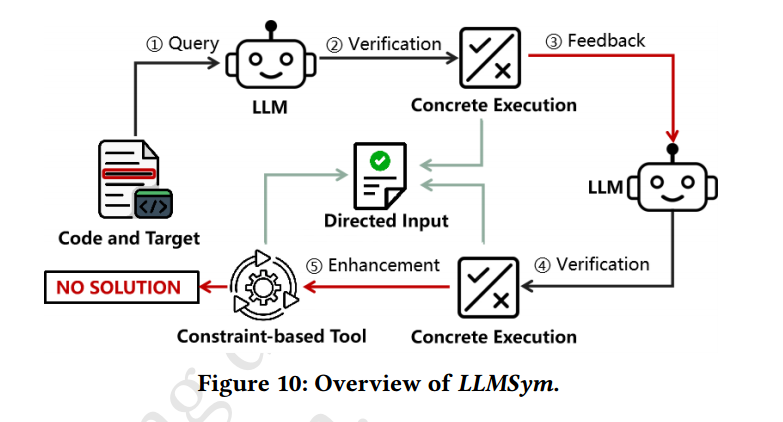
这一部分简单介绍了一下LLM和传统约束求解器结合之后的架构图,从上图能够大致看明白整个原理如何,事实上,在我看这篇论文的时候一直是比较期待这一部分的内容,但文章作者的重心主要放在了 LLM 和传统约束求解器之间性能的比较,而对于这一部分内容也只用了半页内容,我觉得有些粗糙了,同时从上面的这个 LLMSym 的架构来看,实际上也是将步骤分开了,LLM 处理两次,然后在最后不能产生有效输入的情况下再交给约束求解器,这实际上并没有发挥 LLM 更大的优势,比如说让 LLM 指导约束求解器(比如在需要某些外部输入的情况下)生成结果,那这样效果肯定是要更好的,上图中实际上性能虽然会提升,但本质上就是让这两个东西合起来各跑一遍,我认为创新性还是比较低的。
others
- 符号执行 benchmark logic_bombs
- opensource LLMs(StarCoder2,CodeLlama,CodeQwen)
- constraint-based tools (Angr,KLEE,CrossHair,EvoSuite)
tailored:定做的
panacea:灵丹妙药
stark:完全的,朴实的
curate:筹办,展出
nuanced:微妙的
hallucination:幻觉
heuristics:启发式
cutting-edge:先进的
CodeLlama, leveraging the advancements of Llama, showcases exceptional performance, offering cutting-edge capabilities such as superior infilling.
on par:相当
The results demonstrate that the performance of GPT-3.5 on our datasets is on par with the constraintbased tools.
- Title: 看论文 Towards Understanding the Effectiveness of Large Language Models on Directed Test Input Generation
- Author: henry
- Created at : 2024-10-31 00:56:16
- Updated at : 2024-10-31 00:58:36
- Link: https://henrymartin262.github.io/2024/10/31/PathEval_Preprint/
- License: This work is licensed under CC BY-NC-SA 4.0.