
看论文 UBfuzz Finding Bugs in Sanitizer Implementations

论文链接:https://shao-hua-li.github.io/assets/pdf/2024_asplos_ubfuzz.pdf
代码仓库:https://github.com/shao-hua-li/UBGen
看论文 UBfuzz: Finding Bugs in Sanitizer Implementations
在介绍论文之前先看一个有趣的示例 test.c
1 | struct a { int x;}; |
可以通过分析很明显知道这个程序存在第8行越界访问,试试 ASAN 能不能检测的到这个问题
1 | henry@henry:~/Documents/test$ clang -O0 -fsanitize=address test.c |
不开启编译优化的时候,可以看到是可以正常检测出来的,但是我们再以另外一种角度去测试
1 | henry@henry:~/Documents/test$ clang -O3 -fsanitize=address test.c |
可以看到在启用了高级优化之后,ASAN 并没有检测到这一漏洞,从而错失了漏洞发现的机会
1 Introduction
这篇论文主要是研究 sanitizer 的漏报问题,并提出了一个测试框架的思路,简单来说就是找到存在 UB(未定义的程序行为),然后再去测试 sanitizer 能否检测到这个问题,如果没有检测到,那么就认为这个 sanitizer 可能存在 bug。
关于上面这个想法引出了两个问题,第一个就是 UB 程序的生成;第二个是编译器优化让 sanitizer 的分析变得复杂化。
关于第一个问题,作者提出的解决方案是——
,尽管已经有了可以自动生成程序的工具,如Csmith,但是如果是生成 UB 程序这些工具还不够,文章中采用的思路是,通过静态分析和动态分析来解析程序的运行时状态,然后找到一个位置来加入语句,从而引入 UB。拿前面的程序举例,删除掉第七行的 k=2就不存在 UB,反之如果在经过分析后,知道令k=2会引入溢出,那么就完成了一个 UB 程序的生成。关于第二个问题,其实并不是说开了
-O0的时候有报告信息,而开了-O3的时候没有报错,就直接判断 sanitizer 存在问题是不可靠的,原因在于在编译器优化的过程中,可能会消除掉程序中存在的一些 UB,从而导致程序本身相比于-O2时没有了原来的问题。作者给出的解决方案就是——
,将同一个程序编译为两个不同的二进制文件b1(-O0)和b2(-O2),如果b1存在报错,b2不存在,这时候就通过debug的方式,去追踪路径,如果两个二进制程序都能到达崩溃点(crash-site),这时候就认为是 sanitizer 产生了漏报问题(河狸)。
贡献:
- 引入了
生成 UB 程序 - 提出
解决分析漏报时编译器和 sanitizer 之间的矛盾 - 自动化工具 UBFuzz
- 提交产出
2 Illustrative Examples
2.1 UB Program Generation
1 | 1 struct a { int x }; |
这里通过一个示例来了解 UB 程序生成,上面代码部分中没有标行号的是源程序(种子程序)。生成主要分为三步:
- 通过定位程序中存在的内存访问语句,从而在源程序中插入分析语句
LOG_BUF(1,2)——静态 - 动态执行收集 buffer 的内存范围信息
- 根据给定目标,引入对应的 UB 语句(3)
经过上面三个步骤就生成了一个 UB 程序,当然再具体过程中还需要 k 值的确定,原因是 ASAN 只能最多检测 32 字节的溢出。
2.2 Crash-Site Mapping as the Test Oracle
是对前面第二个问题的进一步说明,这里重点关注后面的验证,即为什么采用
3 Approach
3.1 UB Conditions and Shadow Statement
关于这一部分理解下面的表格即可

这里对每一列进行说明:
- 第一列列出了程序中存在的一些 UB 行为,比如说缓冲区溢出,UAF 等;
- 第二列是对应可能存在 UB 的语句
- 第三列是保证上面的语句不会存在 UB 行为的条件
- 第四列就是需要插入
的位置 - 第五列列出了对应
需要完成的目标 - 最后一列就是最终插入的具体的语句(
)
3.2 UB Program Generator
具体算法如下:

GetMatchedExpr(·)
负责生成 E 集合,每个 E 中的元素包括对应的语句以及其位置
Program Profiling — Profile(·)
- 所有在表达式中的值被记录
- 所有堆栈的释放和分配地址信息
活跃区域是指程序执行过程中,某个变量或表达式在某个时刻具有有效值的范围。也就是说,在这个区域内,表达式已经被计算并且结果可以被使用
这里定义了几个查询语句:
:如果 e 位于活跃区域,则返回true,否则返回false。实则就是来检查 在 中是否有值。 :返回 e 的值 :如果 e 是一个指针或者一个数组,则返回 e 所指向的内存范围,若已被释放,返回 false :返回表达式 e的作用域(scope),即e被定义和使用的上下文范围
Shadow Statement Synthesis and Insertion
— SynShadowStmt(·) & Insert(·)
这一部分对前面
:引入辅助变量 ,使得原语句变为 , ,其中 x 来自 , 通过计算 得到 :对于指针也是一样的,跟数组同理 :不需要使用查询语句,在 use 前 free 掉就可以了 :Δ(𝑒𝑥𝑝𝑟) 为 𝑝 = 𝑞,保证 的作用范围不在 中 :让指针为 0 即可 :引入辅助变量 ,其中 ,x 和 y 的值直接通过 来获得,对于 采用蒙特卡罗算法去在区间内抽样,使得能够溢出 :同理,引入辅助变量,让移位操作溢出 :引入辅助变量让分母为 0 即可 :直接引入辅助变量 即可
3.3 Crash-site Mapping as the Test Oracle

Definition :
:A binary is compiled from program 𝒫 and running results in a crash. We denote the last executed instruction as . If corresponds to the line 𝑙 and offset 𝑜 in 𝒫, then the crash site of is .
4 Empirical Evaluation
Implementation
UBFuzz 总共包含 2000 行 c++ 代码,4400 行 python 代码
具体实现如下:
- 使用Clang的 libtools 实现表达式匹配
- 使用程序插桩实现
插入分析 - 使用 LLDB 跟踪记录
中所需的信息,并使用其支持的 python API 来完成整个自动化分析过程
Compilers and sanitizers
选择使用 GCC 和 llvm,以及 ASAN,UBSAN 和 MSan。
Seed programs
选择使用 Csmith 来完成
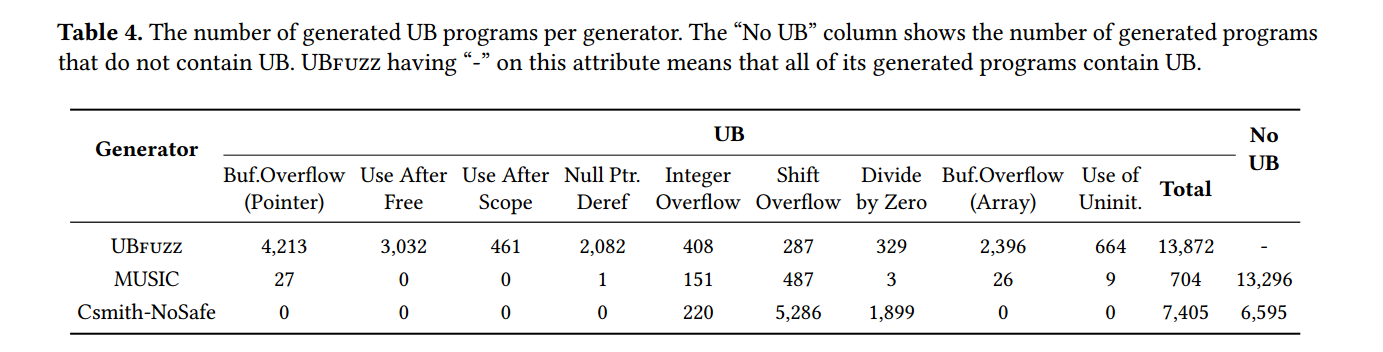
以下给出了一些 UBFuzz 的具体实验结果,有兴趣的读者可以看原论文
Bug Finding
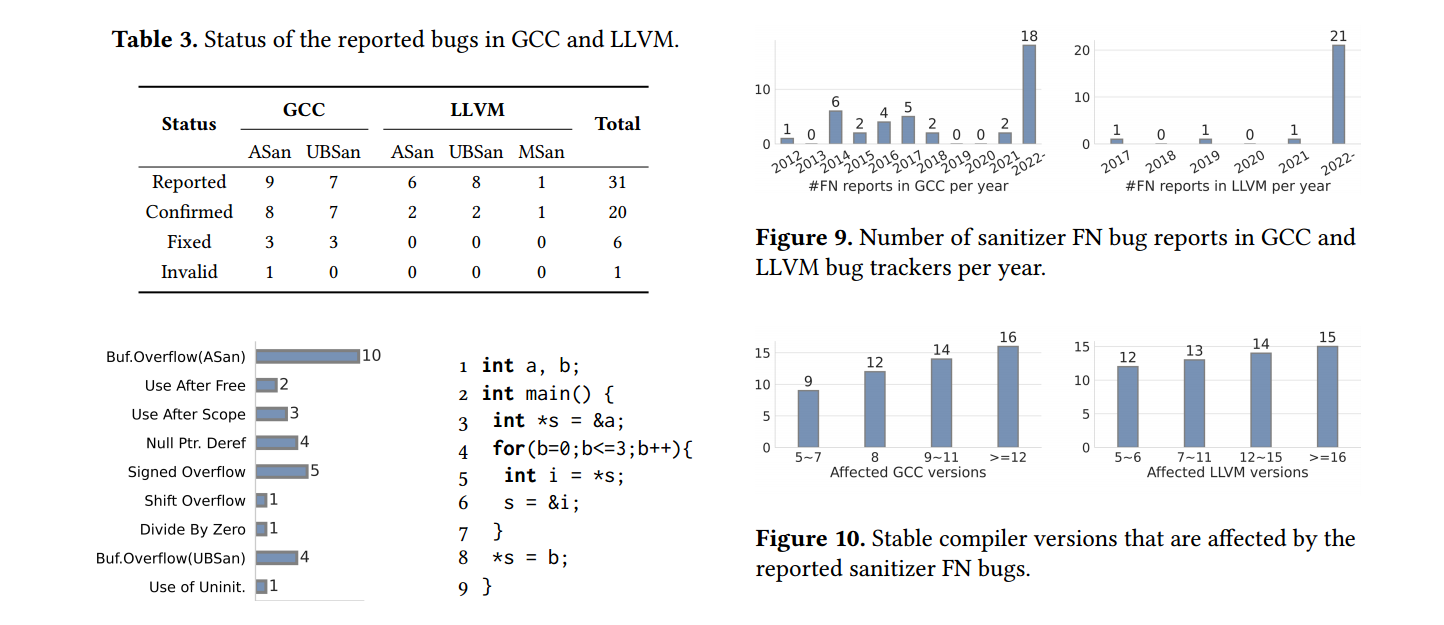
Effectiveness of UB Program Generator
Case Study

这里给出了一些比较有代表性的 sanitizer 漏报的代码示例,可以看到对于一些比较简单的代码,sanitizer 还是有可能会漏报。
- Title: 看论文 UBfuzz Finding Bugs in Sanitizer Implementations
- Author: henry
- Created at : 2024-09-30 20:51:20
- Updated at : 2024-09-30 21:14:58
- Link: https://henrymartin262.github.io/2024/09/30/UBFuzz/
- License: This work is licensed under CC BY-NC-SA 4.0.