AFL 使用技巧总结

AFL 使用技巧总结
快速简易上手
- 使用 afl-cc 编译项目或者库,比较常见的做法如下:
1 | CC=afl-cc CXX=afl-c++ ./configure --disable-shared |
- 如果项目从 stdin 读入,则 afl-fuzz 如下
1 | ./afl-fuzz -i seeds_dir -o output_dir -- \ |
如果程序从文件中获取输入,则可以在程序的命令行中放置@@,AFL++将在其中放置一个自动生成的文件名。
- 可以从 output_dir 中找到输出的结果,如 crash 和 hangs,若程序直接是从 stdin 中读入的,则可以将 crash 的结果直接喂给程序,命令如下
1 | cat output_dir/crashes/id:000000,* | /path/to/tested/program [...program's cmdline...] |
源码模糊测试
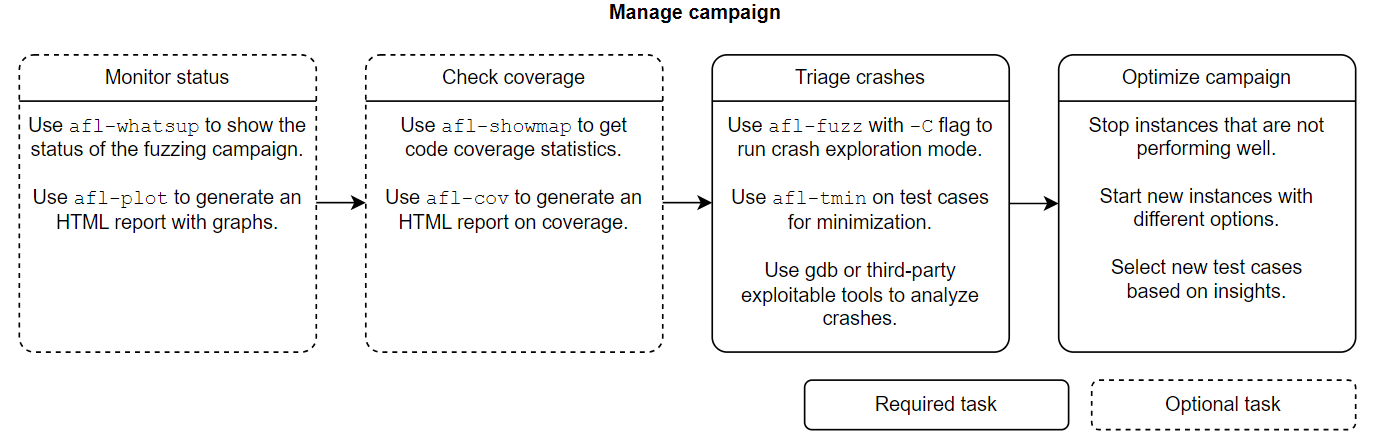
当有目标程序的源码时,在进行模糊测试时,一般遵循以下步骤
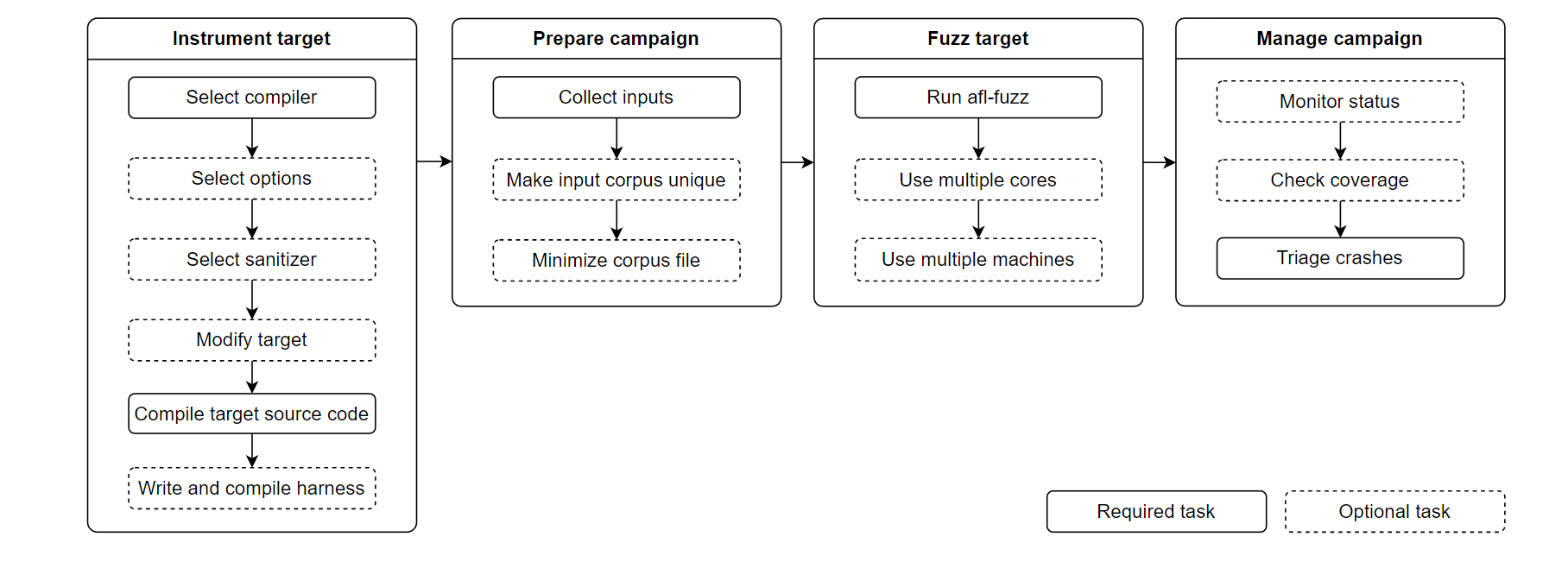
下面来分别说明每个部分具体工作
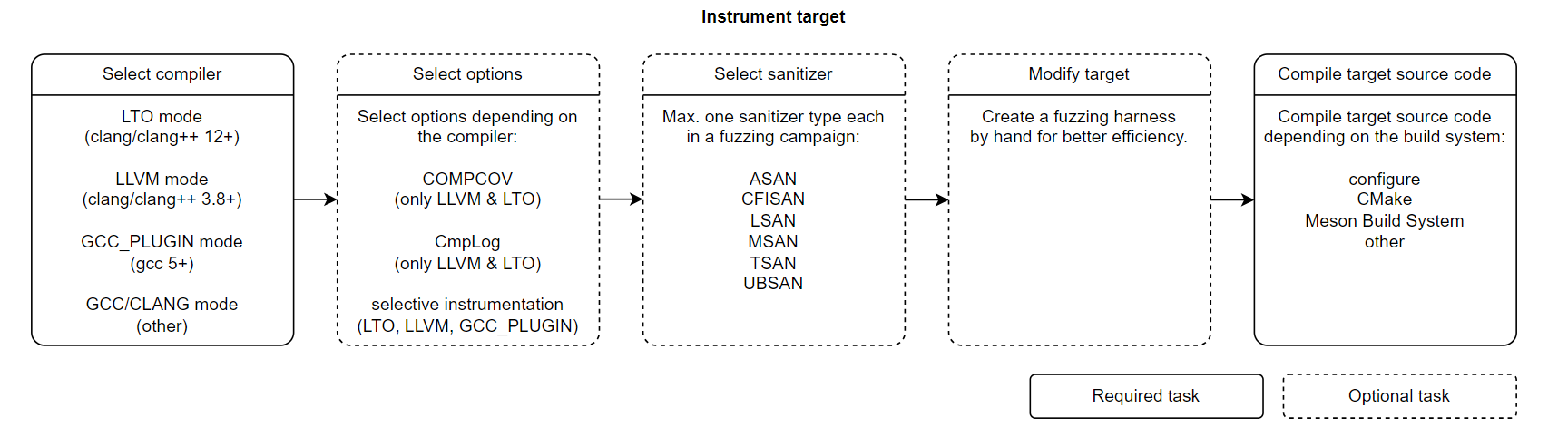
Instrument target
Preparing the fuzzing campaign
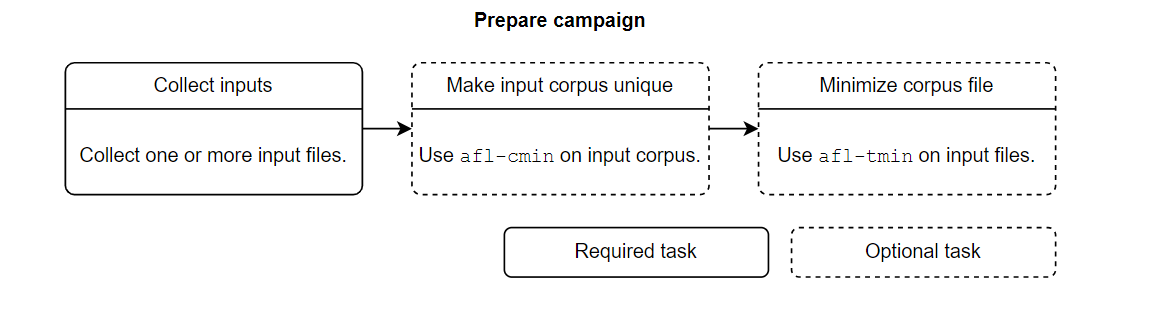
这里需要注意的是 afl-cmin 的作用是将冗余重复的文件删掉,而 afl-tmin 的作用是将文件本身的内容进行简化。
Fuzzing the target
Managing the fuzzing campaign
2. fuzzing in depth
2.1 Instrumenting the target
- 选一个合适的编译器,用来对目标进行插桩,模式选择如下
1 | +--------------------------------+ |
LTO和GCC_PLUGIN通常提供更好的性能,而LLVM和GCC则适合更广泛的环境
可以通过以下方法之一选择 afl-cc 编译器的模式:
使用符号链接到 afl-cc:afl-gcc、afl-g++、afl-clang、afl-clang++、afl-clang-fast、afl-clang-fast++、afl-clang-lto、afl-clang-lto++、afl-gcc-fast、afl-g++-fast(推荐!)。
AFL_CC_COMPILER使用环境变量MODE。将 –afl-
MODE命令行选项传递给编译器。CFLAGS,CXXFLAGS,CPPFLAGS1
2export CFLAGS="--afl-MODE=xxx"
export CXXFLAGS="--afl-MODE=xxx"MODE的值可以为如下:- LTO (afl-clang-lto*)
- LLVM (afl-clang-fast*)
- GCC_PLUGIN (afl-g*-fast) or GCC (afl-gcc/afl-g++)
- CLANG(afl-clang/afl-clang++)
Selecting sanitizers
以下清理器在 AFL++ 中有内置支持:
- ASAN = Address SANitizer,查找内存损坏漏洞,如释放后使用、空指针取消引用、缓冲区溢出等。
export AFL_USE_ASAN=1编译前启用。 - MSAN = Memory SANitizer,查找对未初始化内存的读取访问,例如在设置之前定义并读取的局部变量。
export AFL_USE_MSAN=1在编译之前启用。 - UBSAN = 未定义行为 SANitizer,根据 C 和 C++ 标准,查找发生未定义行为的情况,例如,将两个有符号整数相加,结果大于有符号整数可以容纳的数。
export AFL_USE_UBSAN=1编译前启用。 - CFISAN = 控制流完整性 SANitizer,查找控制流非法的实例。最初,这是为了防止返回导向编程 (ROP) 漏洞链发挥作用。在模糊测试中,这主要是为了检测类型混淆漏洞 - 然而,这是最重要和最危险的 C++ 内存损坏类之一!
export AFL_USE_CFISAN=1在编译之前启用。 export AFL_USE_TSAN=1TSAN = Thread SANitizer,查找线程竞争条件。编译前启用。- LSAN = Leak SANitizer,用于查找程序中的内存泄漏。对于开发人员来说,这非常有价值。请注意,与上面的其他清理器不同,这需要
__AFL_LEAK_CHECK();添加到发现需要泄漏检查的目标源代码的所有区域!在编译之前启用export AFL_USE_LSAN=1。要忽略某些分配的内存泄漏检查,__AFL_LSAN_OFF();可以在分配内存之前和__AFL_LSAN_ON();之后使用。这两个宏之间分配的内存将不会检查内存泄漏。
Modifying the target
当源代码中有存在类似计算校验和和哈希这种费时操作时,可以直接在源码中将它们删除,格式如下
1 | #ifdef FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION |
Instrumenting the target
始终将想要检测的库编译为静态库,并将它们链接到目标程序
配置选项
对于configure构建系统,这通常通过以下方式完成:
1 | CC=afl-clang-fast CXX=afl-clang-fast++ ./configure --disable-shared |
对于 CMake 构建系统,这通常通过以下方式完成:
1 | mkdir build; cd build; cmake -DCMAKE_C_COMPILER=afl-cc -DCMAKE_CXX_COMPILER=afl-c++ .. |
对于 Meson Build System 使用下面的命令设置
1 | CC=afl-cc CXX=afl-c++ meson |
Better instrumentation
如果只是按原样对目标程序进行模糊测试,在一定程度上是效率非常低下的。
为了让 fuzz 的速度更快,就需要所谓的persistent mode,这会让速度快得多,但需要编写一个源文件,该文件专门调用要模糊测试的目标函数,以及一些特定的 AFL++ 函数。详细信息可以见这里 persistent mode 。
2.2 Preparing the fuzzing campaign
a) 收集输入
其实就是语料库收集,官方这里给了一个 testcase 可以拿来用
b)使输入语料库独一无二
使用 AFL++ 工具afl-cmin从语料库中删除不会在目标中产生新路径/覆盖的输入:
将步骤 a 中的所有文件放入一个目录中,例如
INPUTS。运行 afl-cmin:
如果目标程序要通过 fuzzing 调用
bin/target INPUTFILE,则将目标程序读取的 INPUTFILE 参数替换为@@:1
afl-cmin -i INPUTS -o INPUTS_UNIQUE -- bin/target -someopt @@
如果目标从 stdin(标准输入)读取,则只需省略
@@,因为这是默认值:1
afl-cmin -i INPUTS -o INPUTS_UNIQUE -- bin/target -someopt
强烈建议执行此步骤,因为此后测试用例语料库不会再充斥着重复内容,从而减慢模糊测试的进度!
c) 最小化所有语料库文件
实际上就是在对原始文件缩小的情况下,仍然能够保持同样的覆盖效果,执行步骤如下
1 | mkdir input |
此步骤也可并行执行,例如使用parallel。
3. Fuzzing the target
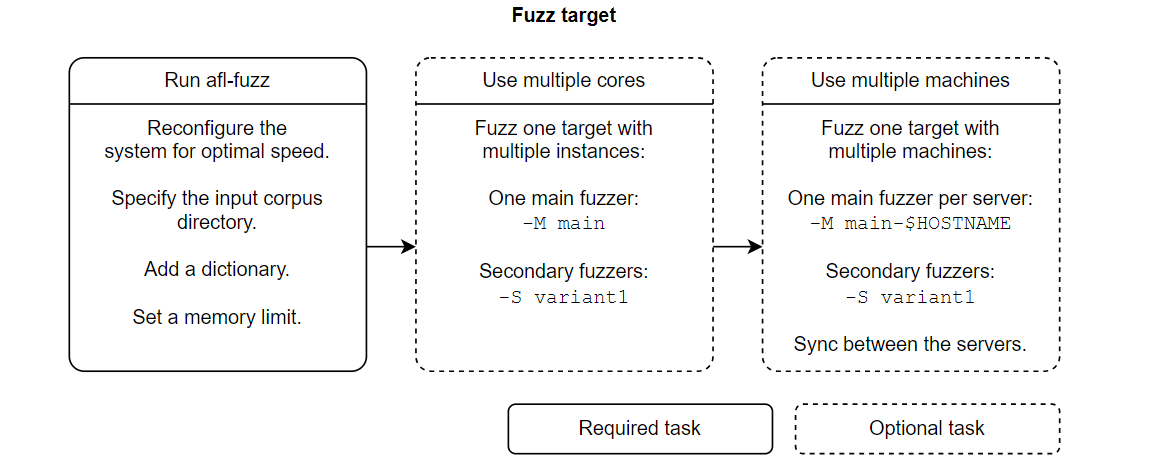
3.1 加快执行速度
执行下面的两个命令,会使得 afl-fuzz 的速度得到增强,但是同时系统的防护能力也会减弱。
1 | sudo afl-system-config |
3.2 必要时添加字典
添加词典的方式有如下操作:
- 直接通过告诉 afl-fuzz 加载字典
-x dictionaries/FORMAT.dict,这里给出了一些字典库 。 - 在使用
afl-clang-lto时,可以进行自动词典生成 - 在使用
afl-clang-fast时,AFL_LLVM_DICT2FILE=/full/path/to/new/file.dic这个设置可以在目标编译期间自动生成字典。添加AFL_LLVM_DICT2FILE_NO_MAIN=1不解析主函数(通常是命令行参数解析)通常也是可行的。 - 还可以在目标独立运行期间自己生成字典,请参阅 utils/libtokencap/README.md 。
- 最后,当然,也可以手动编写字典文件。
3.3 控制内存使用和超时
其实就是设置 -m 和 -t 两个参数,在默认情况下,afl-fuzz 不强制执行内存限制,系统可能会耗尽内存,所以可以使用 -m 减少内存分配。
在fuzz一些比较垃圾的样本时,可能会浪费比较多的时间,所以通过 -m 设置内存,还是会在一定程度上提高效率的。
3.4 多台机器 fuzz
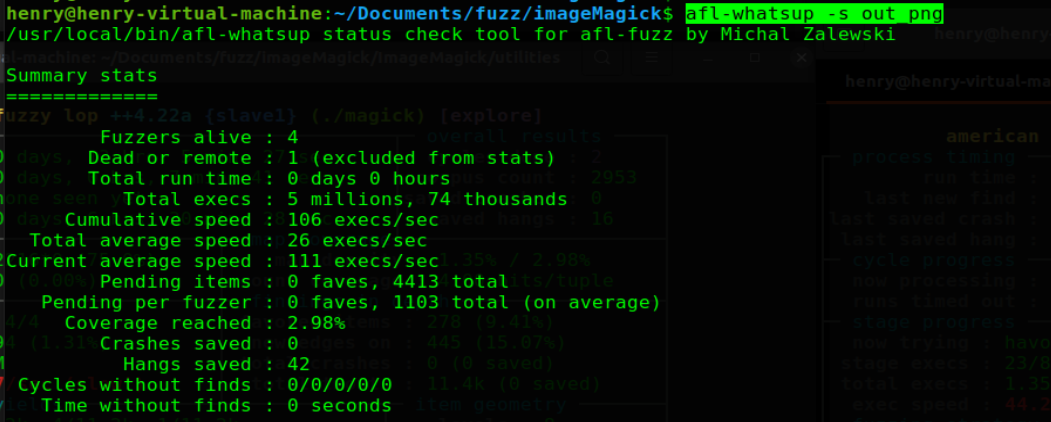
3.5 fuzz 的状态检查
这个操作可以通过 afl-whatsup 来实现,命令如 afl-whatsup -s out_png,在多台机器中,需要等待同步之后在执行该命令,或者在每台机器上单独执行这个命令。
同时还可以执行 afl-plot out_png/default ./plot,使用这条命令生成AFL的图表。
3.6 停止和重新启动AFL模糊测试的运行
中断:Control-C 可以中断当前正在运行的afl-fuzz实例。
重新启动:使用相同的命令行,但需要将-i目录替换为-i -,表示为上一次这表示从上一次的状态继续,另一种方法是设置环境变量 AFL_AUTORESUME=1,这将自动使afl-fuzz在启动时恢复到之前的状态,而不需要手动修改命令行。
运行临时模糊测试实例:通过设置环境变量 AFL_BENCH_JUST_ONE=1 和 AFL_FAST_CAL=1,可以加快模糊测试的速度并使其只处理一个实例。命令如下:
1 | afl-fuzz -i newseeds -o out -S newseeds -- ./target |
注意事项:
--表示后面的./target是要模糊测试的目标程序,而不是选项或参数。这在处理目标程序的名称时特别重要,因为目标程序的名称可能与某些选项重名
3.7 检查覆盖率,以及提升覆盖率的一些思路
1 | afl-showmap -C -i out -o /dev/null -- ./target -params @@ |
可以通过上面的命令来查看覆盖率覆盖信息,同时可以借助这些信息来想办法提升覆盖率,比如
- 检查覆盖的具体代码行:了解哪些代码行被触达,哪些未被触达,可以帮助你更好地评估测试效果。这些可以使用 afl-cov 来做到,
- 针对未覆盖区域的操作:对于未覆盖的区域,可以找对应的样本来触发这些路径
- 处理核心资源:
export AFL_NO_AFFINITY=1:使模糊测试不绑定到特定核心。export AFL_TRY_AFFINITY=1:尝试绑定到某个核心。 - 覆盖率的限制:可能输入示例只会涉及到部分 API
3.8 fuzz 的时间参考
如果经过一天或者一周都没有出现新的路径,那么就可以认为不会出现新的crash之类的了,可以考虑换种思路。
3.9 提升 fuzz 的速度
使用持久模式:实现2到20倍的速度提升。
设置环境变量:
- 如果不使用共享内存持久模式,设置
AFL_TMPDIR指向tempfs位置。
优化Linux内核:
修改
/etc/default/grub,设置GRUB_CMDLINE_LINUX_DEFAULT为:1
ibpb=off ibrs=off kpti=off l1tf=off mds=off mitigations=off no_stf_barrier noibpb noibrs nopcid nopti nospec_store_bypass_disable nospectre_v1 nospectre_v2 pcid=off pti=off spec_store_bypass_disable=off spectre_v2=off stf_barrier=off
更新grub并重启(注意:这会降低系统安全性)。
文件系统优化:
- 在ext2文件系统上运行,并使用
noatime挂载选项,以提高速度。
利用多核处理器:确保使用所有核心。
首次启动前配置:在重启后运行sudo afl-system-config。
3.10 发现 crash 之外的内容
暂时不太关心,参考文档
4. Triaging crashes
基于覆盖率的崩溃分组通常会产生一个较小的数据集,可以通过手动方式或简单的GDB或Valgrind脚本快速分类
崩溃探索模式(crash exploration mode)用于深入分析导致程序崩溃的输入,以帮助发现和理解崩溃背后的原因。具体用途包括:
- 代码路径枚举:该模式通过使用崩溃的测试用例,快速探索程序的所有可达代码路径,保持程序在崩溃状态。
- 控制权分析:生成的结果集可以帮助分析攻击者对崩溃地址的控制程度,评估潜在的安全漏洞。
- 提高利用率:通过识别不同的执行路径和可能的输入变异,帮助安全研究人员理解崩溃是否可被利用,并探索可能的利用方式。
AFL++ 中的另一个工具是 afl-analyze 工具。它获取一个输入文件,尝试按顺序翻转字节并观察测试程序的行为。然后,它会根据哪些部分看起来是关键的、哪些部分不是关键的,对输入进行颜色编码,通常可以快速洞察复杂的文件格式。
casr-aflCASR 工具可轻松分类 AFL++ 发现的崩溃。报告是聚合的,包含严重性和其他信息。
1 | casr-afl -i /path/to/afl/out/dir -o /path/to/casr/out/dir |
5. 知识点总结
5.1 afl 的模式和特性
AFL 中不同的模糊测试插桩模式及其特性
1 | |------------- FEATURES -------------| |
- 关于
MODES的子模式解释如下:
PCGUARD:
- 描述:使用支配树插桩,性能最好,提供更精细的路径覆盖信息。
- 文档:详细信息可以在
README.llvm.md中找到。
LLVM-NATIVE:
- 描述:使用 LLVM 的本地 PCGUARD 插桩,性能较差,但与 LLVM 更好集成。
CLASSIC:
- 描述:使用决策目标插桩,提供基本的路径覆盖信息。
- 文档:详细信息在
README.llvm.md中。
CALLER:
- 描述:在 CLASSIC 模式基础上增加单个被调用者上下文,提供更好的调用关系跟踪。
- 文档:更多细节在
instrumentation/README.ctx.md中。
CTX:
- 描述:在 CLASSIC 模式基础上增加完整的被调用者上下文,提供更全面的调用关系跟踪。
- 文档:详细信息在
instrumentation/README.ctx.md中。
NGRAM-x:
- 描述:在 CLASSIC 模式基础上,结合之前的路径信息,增强对路径的跟踪能力。
- 关于
Features的说明如下:
**NCC (Non-Colliding Coverage)**:
- 描述:非冲突覆盖,可以自动避免重复路径的覆盖,提供更有效的路径探索。
- 文档:详见
instrumentation/README.lto.md。
**PERSIST (Persistent Mode Support)**:
- 描述:支持持久模式,显著提高运行速度,避免每次执行都重新初始化。
- 文档:详见
instrumentation/README.persistent_mode.md。
**DICT (Dictionary in the Target)**:
- 描述:目标程序中使用字典,可通过自动方式或 LLVM 模块传递支持。
- 文档:详见
instrumentation/README.lto.md和instrumentation/README.llvm.md。
**LAF (Comparison Splitting)**:
- 描述:比较分裂,可以增强输入的多样性,详细信息见文档。
- 文档:详见
instrumentation/README.laf-intel.md。
**CMPLOG (Input to State Exploration)**:
- 描述:探索输入与程序状态之间的关系,有助于更好地理解程序行为。
- 文档:详见
instrumentation/README.cmplog.md。
**SELECT (Selective Instrumentation)**:
- 描述:根据文件名或函数名选择性插桩,可以允许或拒绝特定的插桩。
- 文档:详见
instrumentation/README.instrument_list.md。
5.2 afl 相关环境变量
一般环境变量
- AFL_CC:指定要使用的 C 编译器的路径。
- AFL_CXX:指定要使用的 C++ 编译器的路径。
- AFL_DEBUG:启用开发者调试输出,便于排查问题。
- AFL_DONT_OPTIMIZE:禁用优化,通常用于调试,而不是使用默认的
-O3优化选项。- AFL_NO_BUILTIN:禁用字符串比较函数的内置版本(适用于
libtokencap.so)。- AFL_NOOPT:使编译器表现得像一个普通编译器,以通过配置测试。
- AFL_PATH:指定插桩过程和运行时的路径(如
afl-compiler-rt.*o)。- AFL_IGNORE_UNKNOWN_ENVS:忽略未知环境变量,不会显示警告。
- AFL_INST_RATIO:指定要插桩的分支百分比。
- AFL_QUIET:抑制详细输出,减少输出信息。
- AFL_HARDEN:增加代码硬化,以捕捉内存错误。
- AFL_USE_ASAN:激活地址 sanitizer(ASan),用于检测内存错误。
- AFL_USE_CFISAN:激活控制流 sanitizer(CFI San),用于检测控制流错误。
- AFL_USE_MSAN:激活内存 sanitizer(MSan),用于检测未初始化内存的使用。
- AFL_USE_UBSAN:激活未定义行为 sanitizer(UBSan),用于检测未定义行为。
- AFL_USE_TSAN:激活线程 sanitizer(TSan),用于检测线程相关问题。
- AFL_USE_LSAN:激活泄漏检查器(Leak Checker),用于检测内存泄漏。
GCC 插件特定环境变量
- AFL_GCC_CMPLOG:记录比较操作数(用于 RedQueen 变异器)。
- AFL_GCC_OUT_OF_LINE:禁用内联插桩。
- AFL_GCC_SKIP_NEVERZERO:在跟踪计数器上不跳过零。
- AFL_GCC_INSTRUMENT_FILE:根据文件名启用选择性插桩。
LLVM/LTO/afl-clang-fast/afl-clang-lto 特定环境变量
- AFL_LLVM_THREADSAFE_INST:使用线程安全计数器进行插桩,禁用 neverzero。
- AFL_LLVM_SKIP_NEVERZERO:在跟踪计数器上不跳过零。
- AFL_LLVM_DICT2FILE:基于找到的比较生成 AFL 字典。
- AFL_LLVM_DICT2FILE_NO_MAIN:跳过主函数的字典解析。
- AFL_LLVM_INJECTIONS_ALL:启用所有注入钩子。
- AFL_LLVM_INJECTIONS_SQL:启用 SQL 注入钩子。
- AFL_LLVM_INJECTIONS_LDAP:启用 LDAP 注入钩子。
- AFL_LLVM_INJECTIONS_XSS:启用 XSS 注入钩子。
- AFL_LLVM_LAF_ALL:启用所有 LAF 分裂/变换。
- AFL_LLVM_LAF_SPLIT_COMPARES:启用级联比较。
- AFL_LLVM_LAF_SPLIT_COMPARES_BITW:设置级联比较的大小限制(默认 8)。
- AFL_LLVM_LAF_SPLIT_SWITCHES:对开关进行级联比较。
- AFL_LLVM_LAF_SPLIT_FLOATS:对浮点数进行级联比较。
- AFL_LLVM_LAF_TRANSFORM_COMPARES:对字符串函数的比较进行级联。
- AFL_LLVM_ALLOWLIST/AFL_LLVM_DENYLIST:启用插桩的允许/拒绝列表(选择性插桩)。
- AFL_LLVM_CMPLOG:记录比较操作数(用于 RedQueen 变异器)。
- AFL_LLVM_INSTRUMENT:设置插桩模式,如 CLASSIC、PCGUARD、LTO、GCC、CLANG、CALLER、CTX、NGRAM-2..16。
旧环境变量(兼容性)
- AFL_LLVM_USE_TRACE_PC:使用 LLVM 的 trace-pc-guard 插桩。
- AFL_LLVM_CALLER:使用单一上下文敏感覆盖(用于 CLASSIC)。
- AFL_LLVM_CTX:使用完整的上下文敏感覆盖(用于 CLASSIC)。
- AFL_LLVM_NGRAM_SIZE:使用 ngram 先前位置计数覆盖(用于 CLASSIC)。
- AFL_LLVM_NO_RPATH:禁用自定义 LLVM 位置的 rpath 设置。
5.3 persistent mode
关于持久模式(persistent mode)的说明文档见这里 ,简单翻译如下
在持久模式下,AFL++ 在单个进程中多次模糊测试目标,而不是每次执行模糊测试时都fork一个新进程。这是最有效的模糊测试方法,因为速度可以轻松提高 10 倍或 20 倍,且没有任何缺点。所有专业模糊测试都使用此模式。
持久模式要求目标可以在一个或多个函数中调用,并且其状态可以完全重置,以便可以执行多次调用而不会发生资源泄漏,并且之前的运行不会对将来的运行产生影响。
举一个例子就是
1 |
|
原本我们可能需要通过标准输入或者文件输入将内容输入到 buf 中,然后调用 target_function,实际上这样的情况下,每一次这样的过程都是需要一次 fork 系统调用,这增加了内核的开销,所以我们通过设置 __AFL_LOOP(10000),可以在保证单个进程持续对目标进行 fuzz,而且会自动更新 buf 的内容。
上面部分宏定义参考如下(以下宏定义能够在没有 afl-clang-fast/lto 的情况下编译目标):
1 |
|
Deferred initialization
AFL++ 通过确保目标程序只执行一次(在main函数之前停下来,然后克隆当前进程对目标fuzz)来优化性能,这在一定程度上确实优化了性能,但是程序中往往还会存在其他比较耗时性的操作,如在 main 函数开始处解析一个大型的配置文件,那实际上每个fork出来的每个进程又要花时间去解析这些文件,这在一定程度上是非常耗时的,所以说延迟初始化的作用就体现出了。
注意事项:延迟初始化的位置如果选择的不对,可能会让程序出现故障,如下就是一些可能出现故障的例子:
- 创建任何重要的线程或子进程 - 因为 forkserver 无法轻易克隆它们。
setitimer()通过或等效调用来初始化计时器。- 创建临时文件、网络套接字、偏移敏感文件描述符以及类似的共享状态资源 - 但前提是它们的状态对程序以后的行为有显著影响。
- 对模糊输入的任何访问,包括读取有关其大小的元数据
选择位置后,在适当的位置添加以下代码:
1 | #ifdef __AFL_HAVE_MANUAL_CONTROL |
这里使用 #ifdef 进行保护,但包含它们可确保程序在使用 afl-clang-fast/afl-clang-lto/afl-gcc-fast 以外的工具编译时继续正常工作。
Persistent mode
该操作的基本结构如下:
1 | while (__AFL_LOOP(1000)) { |
为什么说这个循环里面一般会放一些无状态的 API 呢,或者怎么理解这个无状态,简单理解就是,这里的操作不会影响后续的一些操作,可以一直重置状态。这里的重置状态就是我们每次 call func 结束之后,可以立马更新数据,进入到下一次同样的操作中,下面的指令就是一个例子。
1 | while (__AFL_LOOP(1000)) { |
Shared memory fuzzing
通过共享内存的方式又可以极大的提高 fuzz 的效率,这一点理解上不难,简单来说省去了每一次过程中分配内存
,释放内存等耗时操作,具体使用如下。
在 #include 指令之后,main 函数之前可以设置下面的命令。
1 | __AFL_FUZZ_INIT(); |
设置共享内存,放在 __AFL_LOOP 之前
1 | unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; |
下面这个命令放在__AFL_LOOP 循环的第一行
1 | int len = __AFL_FUZZ_TESTCASE_LEN; |
5.4 afl-fuzz 参数解析
必需参数
- -i dir:指定包含测试用例的输入目录。可以使用
-来恢复上次的模糊测试(查看 AFL_AUTORESUME)。 - -o dir:指定用于存储模糊测试发现的输出目录。
执行控制设置
- -P strategy:设置固定的变异策略:
explore(专注于新的覆盖路径)exploit(专注于触发崩溃)- 你还可以设置在没有新发现后切换到
exploit模式的时间(默认 1000 秒)。
- -p schedule:指定功率调度计算种子的性能得分,选项包括:
explore(默认)fastexploitseekraremmoptcoelinquad
- -f file:指定模糊程序读取的位置(默认为
stdin或@@)。 - -t msec:为每次运行设置超时(自动缩放,默认为 1000 毫秒)。在值后加
+可自动计算超时,值为最大值。 - -m megs:为子进程设置内存限制(以 MB 为单位,0 表示无限制,默认为 0)。
- -O:使用仅二进制插桩(FRIDA 模式)。
- -Q:使用仅二进制插桩(QEMU 模式)。
- -U:使用基于 Unicorn 的插桩(Unicorn 模式)。
- -W:使用带 Wine 的 QEMU 模式进行插桩。
- -X:使用 VM 模糊测试(NYX 模式 - 独立模式)。
- -Y:使用 VM 模糊测试(NYX 模式 - 多实例模式)。
变异器设置
- -a type:指定目标输入格式,选择
"text"或"binary"(默认是generic)。 - -g minlength:设置生成的模糊输入的最小长度(默认 1)。
- -G maxlength:设置生成的模糊输入的最大长度(默认 1048576)。
- -L minutes:使用 MOpt(优化模式),并设置进入节拍模式的时间限制(无新发现的分钟数)。0 表示立即,-1 表示立即并结合正常变异。
- -c program:通过指定为 CmpLog 编译的二进制文件来启用 CmpLog。如果使用 QEMU/FRIDA 或模糊目标为 CmpLog 编译,则使用
-c 0。要禁用 CmpLog,请使用-c -。 - -l cmplog_opts:CmpLog 配置值(例如
"2ATR"):1= 小文件2= 大文件(默认)3= 所有文件A= 算术求解T= 转换求解X= 极端转换求解R= 随机颜色化字节。
模糊测试行为设置
- -Z:使用顺序队列选择,而不是加权随机。
- -N:不删除模糊输入文件(适用于设备等)。
- -n:无插桩模糊测试(非插桩模式)。
- -x dict_file:指定模糊字典(参见 README.md,可以指定最多 4 次)。
测试设置
- -s seed:使用固定的随机数生成器种子。
- -V seconds:模糊测试指定时间后终止(仅模糊时间)。
- -E execs:在大约指定的总执行次数后终止模糊测试(注意:不精确,可能会有额外的执行)。
其他设置
- -M/-S id:分布式模式(-M 设置 -Z 并禁用修剪)。
- 参见 docs/fuzzing_in_depth.md#c-using-multiple-cores 以获取有效的并行模糊测试建议。
- -F path:同步到外部模糊测试队列目录(需要 -M,最多可以指定 32 次)。
- -z:跳过增强的确定性模糊测试(注意旧的 -d 和 -D 标志被忽略)。
- -T text:在屏幕上显示的文本横幅。
- -I command:当发现新崩溃时执行此命令/脚本。
- -C:崩溃探索模式(“秘鲁兔子”模式)。
- -b cpu_id:将模糊测试进程绑定到指定的 CPU 核心(0 及以上)。
- -e ext:模糊测试输入文件的文件扩展名(如有需要)。
CFLAGS=”-fsanitize=address”
- Title: AFL 使用技巧总结
- Author: henry
- Created at : 2024-09-29 10:29:32
- Updated at : 2024-09-29 10:39:27
- Link: https://henrymartin262.github.io/2024/09/29/AFL使用技巧总结/
- License: This work is licensed under CC BY-NC-SA 4.0.