
南大《软件分析》11.0 Pointer Analysis Context Sensitivity I

课程环境:https://tai-e.pascal-lab.net/lectures.html
课程视频:https://www.bilibili.com/video/BV1b7411K7P4
南大《软件分析》11.0 Pointer Analysis Context Sensitivity I
这一节内容讲的是上下文敏感技术,实际上我们前面学的 pointer analysis 都是上下文不敏感,这使得在实际的过程中会缺少精度,而上下文敏感就是为了能够提升分析精度。以下图为例:

对于这段程序,在上下文不敏感中,其最终 PFG 如右边所示,导致最后常量传播的分析结果为 NAC,产生了误报,但实际上 i 会返回一个确定的结果 1,因为 n1 来自 One 这个对象。这里就需要引入上下文敏感技术来提高精度。

直观上来理解,上下文敏感就是尽可能将各调用上下文之间进行隔离,从而保证对象之间的正确传播。

上图给出了上下文不敏感产生不精确结果的原因,即在不同的调用环境下,方法内的变量可能会指向不同的对象,而 CI 将这些部分没有区分,全部传递到其返回的变量,从而造成结果的不准确性。

上下文敏感通过区分不同上下文之间的数据流来提高精度,一种比较传统的上下文敏感策略就是 call site sensitivity(调用点敏感,在 12.0 还会另外集中上下文敏感技术),这个策略实际上就是通过记录调用堆栈信息,来区分不同上下文。

这里指出在基于克隆的上下文敏感指针分析(call site 就是一种基于克隆的上下文敏感技术)中,每个方法都由一个或者多个上下文限定,并且每一个变量也被上下文所限定。后面会有例子来帮助理解这一概念,

为了提高精度,上下文敏感必须也要将堆纳入到考虑对象,如上图所示上下文敏感堆抽象技术在 allocation site 抽象的基础上,提供了一个更细粒度的堆模型。

这里给出了为什么要建立堆抽象的原因。

这里基于一段程序给出了基于 call site 敏感技术不采用堆抽象和采用堆抽象最后得出结果的区别(强烈建议自己对着程序把右边这些结果算一遍,可以加深自己对程序的理解),可以看到 no C.S. heap 最后得到的结果并不精确,而采用堆抽象的 CS 最后可以返回正确的结果。
Context Sensitive Pointer Analysis: Rules
老样子,为了建立出 CS 指针分析算法,还需要设置对应的 Rules。

与前面指针分析的 Rules 大差不差,只不过这里将 context 也作为了考虑范畴,即程序中的方法(method),变量(variables),对象(objects),实例成员(instance fields)都是建立在上下文范畴之内的。
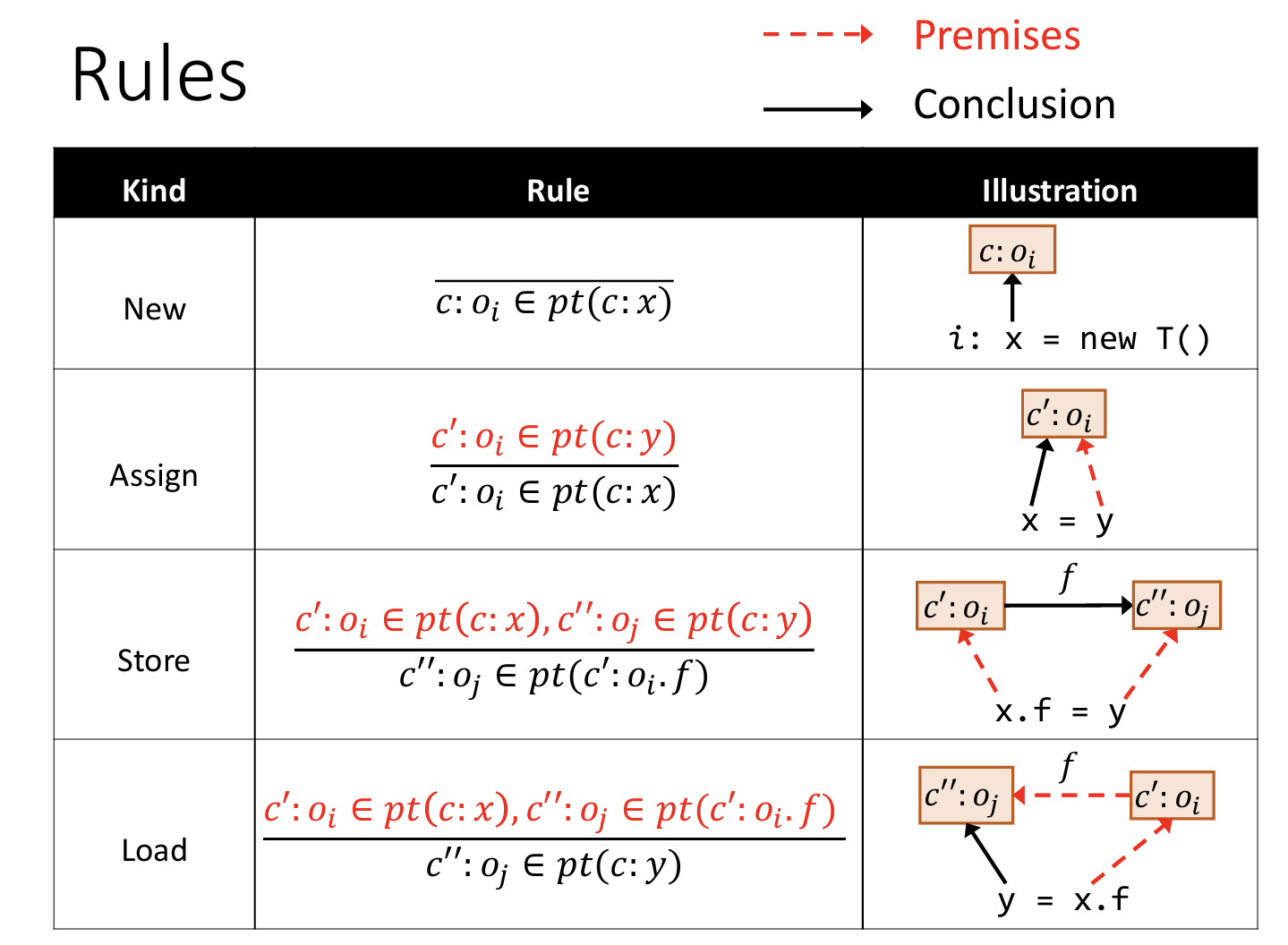
这四种rules对应的表示形式如上图所示。

对应 call 的 rule 比较复杂,所以这里单独将其列出来,对于上面 rule 中的一些上下文变换,需要学会理解,值得注意的是 Select 函数,这里先暂且不管其具体实现(后面会解释),只需要知道它会根据参数返回一个特定的上下文
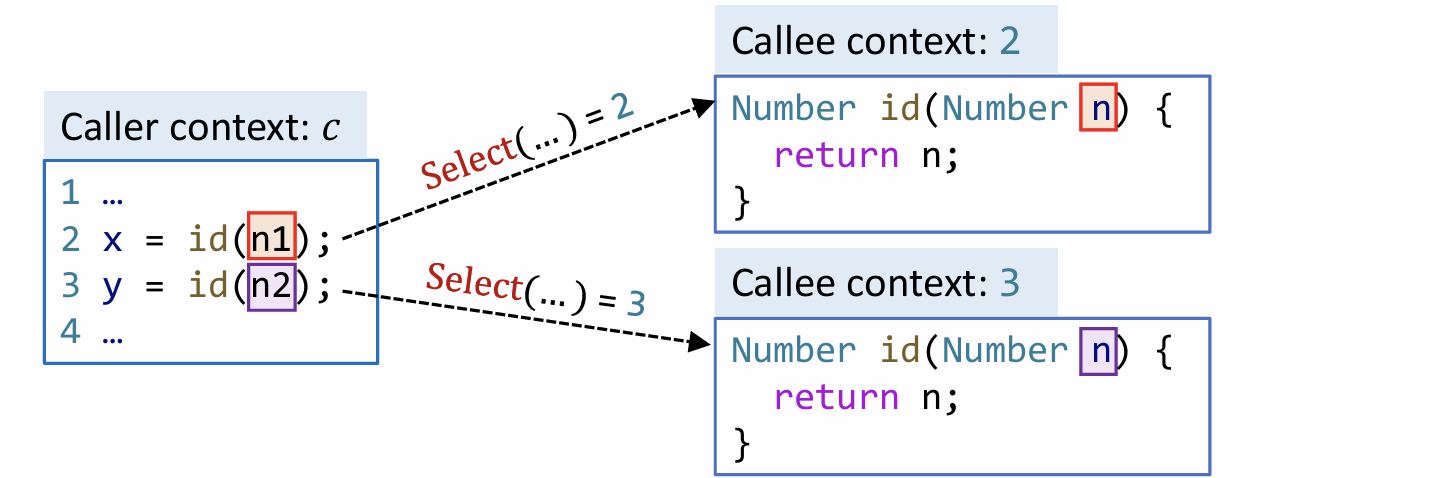
在 call site 敏感技术中,select 的返回结果如上图所示,即返回行号。
思考题

总结
经过这段时间课程的学习,感觉到自己从其它视角对程序的理解更加深刻了。
- Title: 南大《软件分析》11.0 Pointer Analysis Context Sensitivity I
- Author: henry
- Created at : 2024-08-30 11:29:31
- Updated at : 2024-08-30 11:31:29
- Link: https://henrymartin262.github.io/2024/08/30/11.0_Pointer Analysis_Context_Sensitivity_I/
- License: This work is licensed under CC BY-NC-SA 4.0.