
南大《软件分析》10.0 Pointer Analysis Foundations II

课程环境:https://tai-e.pascal-lab.net/lectures.html
课程视频:https://www.bilibili.com/video/BV1b7411K7P4
南大《软件分析》10.0 Pointer Analysis Foundations II
Pointer Analysis with Method Calls
在指针分析中不止我们前面提到的那四种 rules,还包括 method calls(方法调用),由于这一部分比较复杂,因此单独抽出作为一部分进行说明,实际上就是在我们上一部分9.0的内容基础上添加一些额外的处理。
在 8.0 中的第一部分,简单说明了 CHA 在常量传播过程中得到的结果并不精确,同时也指出指针分析的结果是精确的,在这一章节,我们会给出具体的解释。

这里给出了 CHA 和 指针分析之间的区别,以及描述了这两种方法所建立的 call graph 精确程度。

将方法调用 call 作为一条rule,上图给出了call对应rule的具体表达形式,Dispatch 依然是在前面介绍 CHA 时 Dispatch 的概念,同时也给出了其余变量的解释。
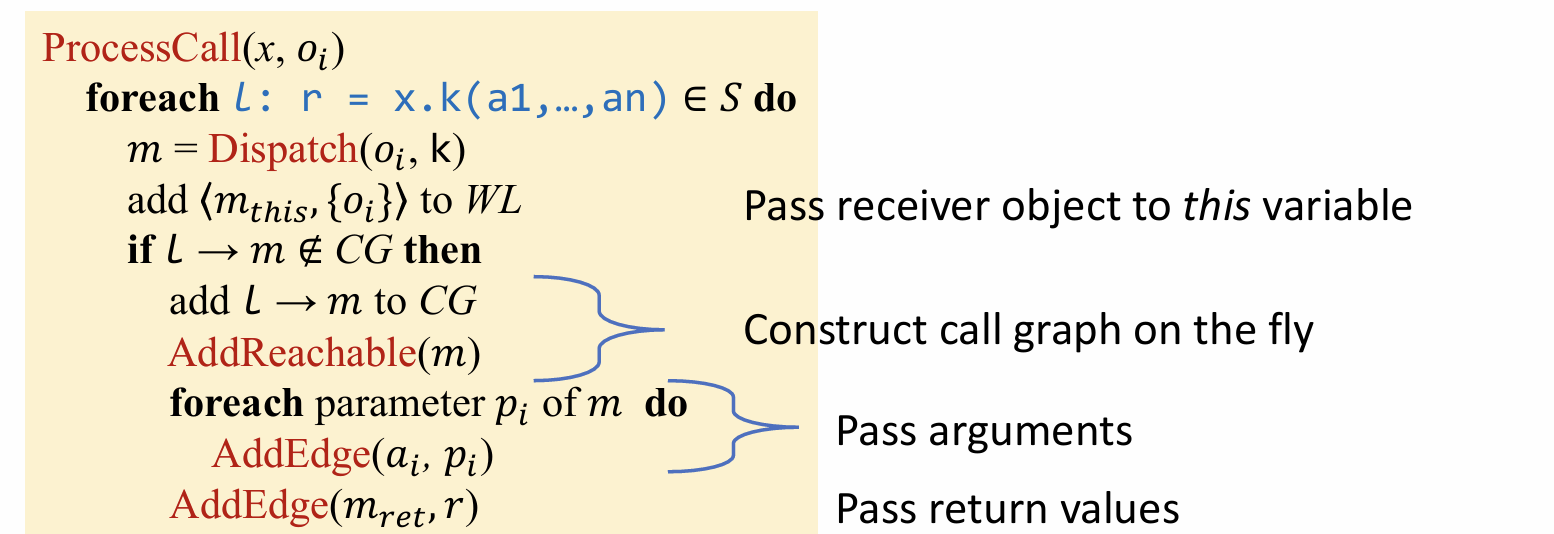
注意事项:如上图所示,我们会将实参到形参也作为 PFG 的一条边,同理将最后的返回值
至于为什么不将 x →

在实际过程中,pt(x) 可能会同时包含 {new A, new B, new C},那么如果我们建立 x →

即 pt(this) = {new A, new B, new C},但是由实际编程知识可以知道,实际上 this 只指向当前自身对象。从而得到了错误的结果,因此这里不会将 x →

这一部分内容指出,过程间指针分析同 call graph 的建立过程是相辅相成的(从后面的例子中可以得到),同时还需要注意的是,call graph 组成了一个 “可达世界”,什么意思呢?其实就是整个算法的处理过程,只考虑那些实际上会被调用的方法,比如说一个类可能有很多方法,但实际上只调用了几个方法,那么在 call graph 建立的过程中只考虑这几个方法,同时也只有这些可达方法才会被分析。
Algorithms

这一部分就是接上一部分,过程间指针分析算法的最终实现(其中还包含了 call graph 的建立)。首先还是老样子,对几个全局变量进行解释:
S:所有可达语句集合,可以理解为程序中所有会被执行的指令
:方法 m 中的语句集合 RM: 所有程序中可达方法的集合
CG:所有的调用边,用来建立 call graph
可以简单来看看这个算法与 9.0 之间的区别,整个算法大体上并没有发生太大变化,增加了三个全局变量 S,RM,CG,还增加了两个新的方法 AddReachable 和 ProcessCall,同时还多了一个参数
AddReachable
简单来说就是将一个可达方法 m 加入到 RM 中,并针对这个可达方法中所有的 new 和 assign 语句,完成对 WL 和相应的 addedge 操作。
ProcessCall
将所有牵扯到 x 所指对象,并调用对应方法(在上图中反映的就是 x.k(…))的语句全部进行遍历,通过 Dispatch 找到方法 k 所属的其最后真正调用位置的方法 m 并返回,同时将 <
Example

来看这样一段程序(蓝色部分),初始全局变量全都为空

执行完 AddReachable 的结果如上

接下来进入到 while 循环,此时由于 a 不牵扯到方法调用和 store/load 语句,因此其执行到 Propagate 结束。

由于程序中存在 b.foo,因此需要进行方法调用处理,算法会进入到 ProcessCall(b,

处理如上图所示,会将 <

最后一轮 ProcessCall 的处理结果如上图所示。由于 B.foo,r,y 都不涉及 store/load 和方法调用,因此执行完 propagate 后结束,最终结果如下:

思考题

- Title: 南大《软件分析》10.0 Pointer Analysis Foundations II
- Author: henry
- Created at : 2024-08-28 19:26:28
- Updated at : 2024-08-28 19:27:51
- Link: https://henrymartin262.github.io/2024/08/28/10.0_Pointer_Analysis_Foundations_II/
- License: This work is licensed under CC BY-NC-SA 4.0.