
看论文 Program Environment Fuzzing

论文链接:https://arxiv.org/pdf/2404.13951
代码链接:https://github.com/GJDuck/EnvFuzz
看论文 Program Environment Fuzzing
1 INTRODUCTION
原有的基于灰盒的模糊器都受限于 fuzz 特定的输入源,如(AFL、AFL++、AFLNet 等等),但是 envfuzz 将程序所有的输入都看做可以用来进行 fuzz 的目标(后面会解释)。
目标:网络协议,linux 下 GUI 程序
总结:
- envFuzz 采用了一种新的方法去捕获程序环境
- 基于在用户内核交互层提出了一个算法用于回放和记录
- envFuzz 是一种通用模糊器,可以用来测试各种程序类型(linux)
2 BACKGROUND AND MOTIVATION
现有的 fuzzer 大都在生成变异输入的时候,不考虑所有的输入,而仅仅针对某一特定的输入类。比如说,AFL 只针对标准输入或命令行指定的文件。AFLnet 只针对特定协议的端口上的网络传输。
传统 fuzzer 的工作流程:
- 输入选择:哪一个输入应该作为 fuzz 的对象
- 环境建模:如何处理其他输入
envFuzz 的核心思想:
- 所有的环境输入都是可以被 fuzz 的
- 环境建模:避免复杂繁琐的建模过程,而是通过变异系统调用来捕获对程序环境的影响
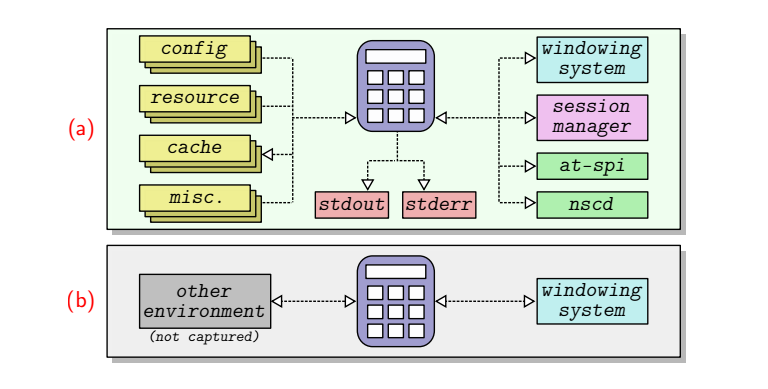
以这个linux下的 GNOME 计算器来进行说明,其在使用情况下,需要各种外部环境资源,而在 envFUZZ 中对上图 a 中所有的外部资源的输入,作为了 fuzz 的对象。
作者所采用的方法是记录(record)所有的环境交互,这个交互可以理解为是系统调用层的环境交互。然后在根据前面记录的交互信息开始迭代重放(replay),只不过在这一步的过程中,有一个重要思想就是会对先前的交互的部分信息进行变异。
3 SYSTEM OVERVIEW
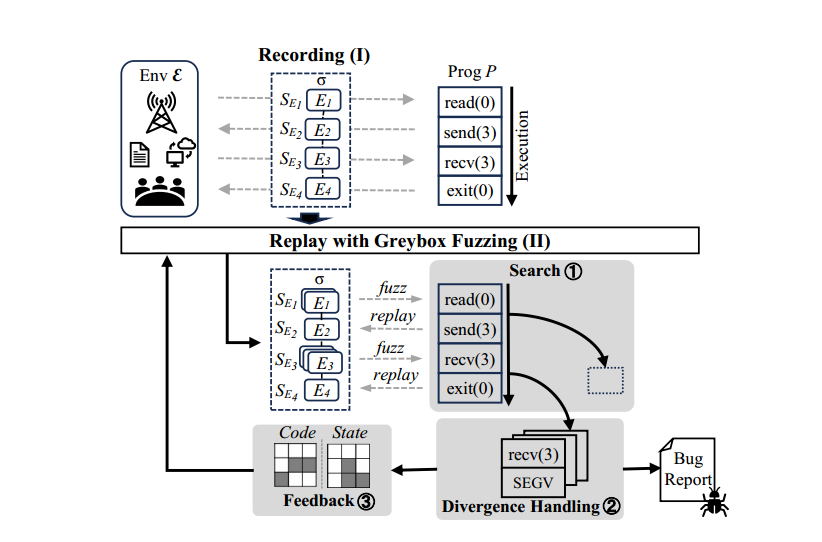
以上面这个图为例子进行说明 envFuzz 的工作流,前面有提到 envFuzz 的工作流程主要分为两个阶段:
(1)record
envFuzz 将会拦截程序 p 在运行过程中产生的所有系统调用,并作为记录保存在𝜎 = [𝐸1, 𝐸2, 𝐸3, 𝐸4] 中,这些信息将会被用在第二个阶段。这些信息具体包括,系统调用号,系统调用参数,缓冲区内容和返回值等等,其实就是将这些信息用来作为第二个阶段的初始种子。
(2)replay
这一阶段又包含两个方面:
- 先通过前面记录的环境交互信息 𝜎,重放以建立第一个阶段中一样的程序状态;
- 使用灰盒测试的方法 fuzz 每一个重建的状态
不同于 AFL 或者 AFLnet fuzz 某一个特定的标准输入/文件或者是一个特定的套接字,envFuzz 的 fuzz 目标是所有记录下来的环境交互状态,replay 的流程大概为:从语料库选出测试的种子S,然后通过变异生成一个新的环境交互。可以简单理解为从系统调用层面进行变异,可以是参数的变化,系统调用顺序的变化,甚至是变异出一个新的系统调用来观察程序的行为。对于一些比较有用的变异将会保存到语料库用于后期进一步利用。
4 ENVIRONMENT FUZZING
4.1 Environment Recording and Replay
首先对于 record 阶段,作者实现了一个系统调用拦截例程。当程序触发一个系统调用时,首先会被该例程所拦截,例程会对当前系统调用的信息进行记录,随后将会该系统调用转发给内核,并等待返回结果,再将返回结果也进行记录,然后再返回给程序。这个过层就称为一次 interaction,用 E 来表示,E 具体所包含的信息有:
- 系统调用号(如 read,write)
- 参数信息(文件描述符,缓冲区指针和缓冲区大小)
- 缓冲区内容
- 当前线程 ID
- 返回值
其次对于 replay 阶段,这一阶段首先会将先前的 record E 信息进行重放,也就是把上面阶段中记录的系统调用进行复现操作,但是 replay 并不会完全重复相同的操作,而是会基于 record 进行一次或多次的变异来观察程序的行为。
作者举了一个例子用来说明其过程,比如说程序 P 执行了一个系统调用 read(0, buf, 100),然后用户输入"quit\n",返回值为 5。这一系统调用过程首先将会被拦截器所拦截,然后记作 record E,在 replay 阶段 envfuzz 可能会将 buf 的内容变异为 "quip\n",在发送给内核,以便发现新的程序行为。
通过上面这一简单的例子,可以大致明白 envfuzz 工作的原理。
4.2 Reflections on Search Challenges
再具体实现时,需要考虑到两个挑战因素:
- 无状态:如何有效的深度探索程序行为
- 吞吐量:如何保证 fuzz 拥有高吞吐量
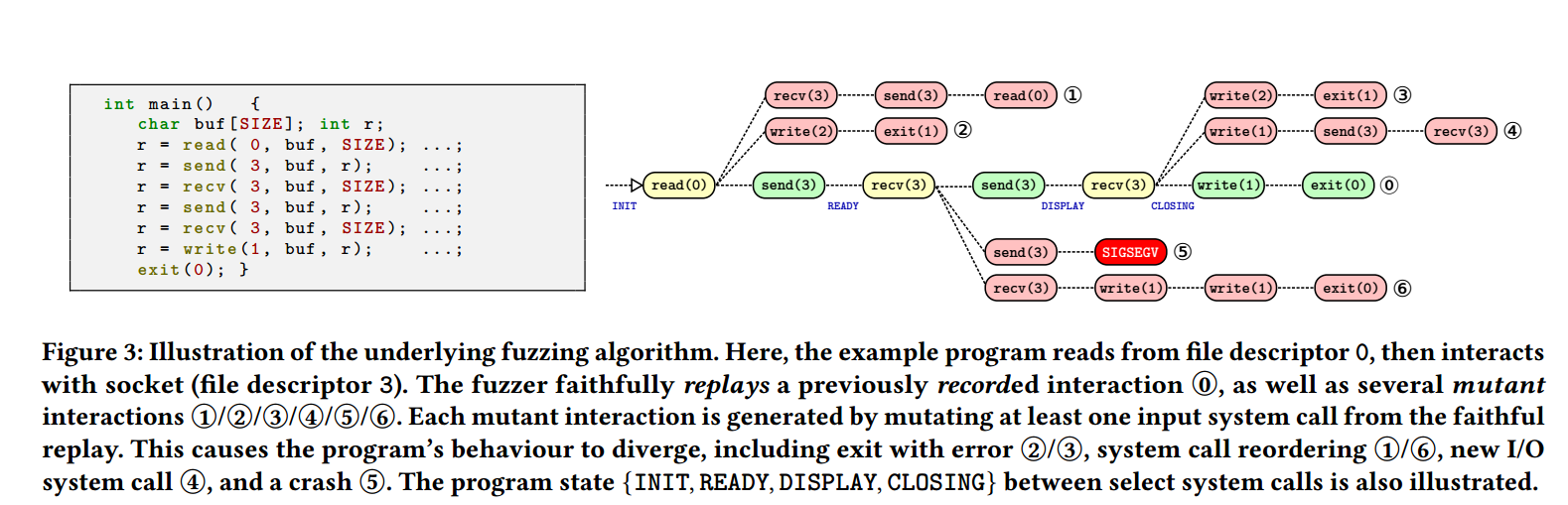
(1)无状态
为了说明第一个挑战,这里以上图为例进行说明,上图左边部分可以看做是一个 GUI 计算器程序执行过程中主要的几个系统调用(实际可能伴随着成百上千的系统调用),程序从一个 INIT 状态开始,首先通过 read(0) 解析配置文件的位置,其次通过 send(3) 向窗口系统套接字发送消息创建一个 GUI 界面。然后进入到 READY 状态,等待接受用户输入的数学表达式 recv(3),然后通过 send(3) 将计算出来的结果返回给界面,这时进入到 DISPLAY 状态,最后用户关闭界面 recv(3),程序进入到 CLOSING 状态,这里程序在退出前发送一条消息给终端然后退出。
可以发现在系统调用层面,程序是有状态的,通过执行一系列系统调用可以让程序从一个状态进入到另外一个状态,这也就意味着我们在 fuzz 有状态的程序时,不能够盲目的 fuzz,而是需要考虑这种状态的识别,以上图为例,不然可能都不能进入到 DISPLAY 一些深层次的程序行为。
基于程序状态识别这块,现有的研究基本上要么建立在需要人工去设置一些操作,要么专门用于特定的输入,那么因为 envFuzz 它是一个 generic 的东西,所以论文中对于状态识别所采用的方法是:每发生一次输入系统调用时,就认为其发生了一次状态转换,还是以上面的图为例子,可以发现在每一次经过 recv() 之后程序的状态就会发生一次改变。
注意事项:需要理解的是为什么要重视这种状态转换,原因就在于每一次状态的变化,就可能意味着产生新的程序行为,从而也就可能产生新的 bug。
当然,作者这里也只是假定认为在发生类似输入类型的系统调用时,程序状态发生改变,实际上还是在有些情况下,程序状态并不会发生改变。对于这种情况,envFuzz 所采用的手段是在未来的变异中降低优先级。
(2)吞吐量
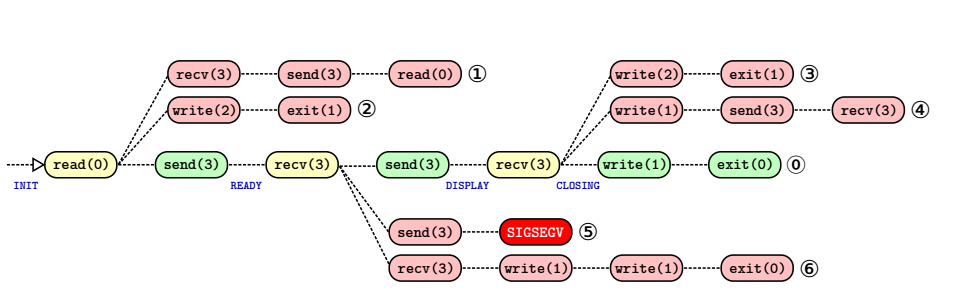
还是拿出这张图来进行说明,为了能够有效的提高吞吐量,不让在 fuzz 某一个特定状态时,重复执行前面的系统调用,论文中采用了这种鱼骨式的 fuzz 策略,简单来说,当检测到存在 recv 这类系统调用时,fuzzer 会 fork 出来新进程,并对系统调用进行变异,从而尝试产生新的行为(也就是上图中分叉红色的部分),当这些 fork 出来的子进程全部都执行结束时,再回到原来正确地方,也就是路径 0,进入 send(3),然后在遇到下一个 recv 操作时,在重复前面的行为,直到最后执行到路径 0 的 exit 操作。
不得不说,这种方法在 fuzz GUI 程序时,确实是一个不错的思想,因为被 fuzz 的程序是有一条主干路径的,也就是说在 fuzz 的过程中,fuzzer 不会盲目进行 fuzz,而是会保证一直沿着这个状态顺序尽可能 fuzz 到每一个输入点。
当然这也给了我们使用 envFuzz 时的一些思想,可以在 record 阶段尽可能多的去触发一些新的如上图的主干路径,也会在很大程度上提高 fuzz 的效率。
4.3 Fuzzing Search Algorithm

上图为 envFuzz 实现的一个核心算法,其实通过前面部分的描述,这个算法其实我们还是可以直接看懂的。需要注意的是 14 行,每当在 spine(前面提到的路径 0) 上检测到一个非输入系统调用,就会原样重复该系统调用,但是只要是输入系统调用,就会进入到 for 循环,envfuzz 将会从语料库 ReplaySyscall 来生成新的执行路径(branch)。
注意事项:可以看到父进程在等待子进程结束后,会根据状态 status 来判断子进程的状态,从而来判断子进程是 crash,还是这个种子
是不是 Interesting 的,简而言之就是说这个种子是否能够产生新的路径等有效的行为,从而将其加入到语料库,用于后期的 fuzz
4.4 Fuzzing Feedback
通过变异后的路径反馈信息,可以判断一个种子是否是有效的,大多数 fuzzer(afl-gcc) 是通过编译插桩的形式来得到路径反馈信息,但由于这里我们是灰盒测试,为了达到一个更通用的效果,论文中采用了 E9AFL ,可以使用静态二进制重写将检测工具直接插入二进制代码中。
当然对于有状态程序,仅仅有分支覆盖被认为是不够的,为了判断一个种子是不是 interesting,我们还需要获取它的状态信息,但是前面也有提到,分析程序状态是一个比较有挑战性的任务(现有的研究,没有好的办法去解决),所以说作者这里采用了另外一种方法,就是在每一次执行完输入调用后,检测其输出以判断是否发生状态转换。这是因为在输入变化后,在一定程度上会伴随着输出的改变(这么一想也确实有点道理)。
5 RELAXED REPLAY FOR DIVERGENCE
细心地同学可能会发现,前面的算法在第 10 行如果判断 isBranch 为真,就会进入 EmulateSyscall 函数,而这一部分就是来讨论这个函数的实现,还是在来通过上面这张图来理解,在通过变异一个输入系统调用后,其后的程序状态可能会发生一些改变,这时候我们需要决定后续需要执行哪些操作,因为这时候程序状态改变,依靠重放原有的系统调用可能会失效,具体来说就是:
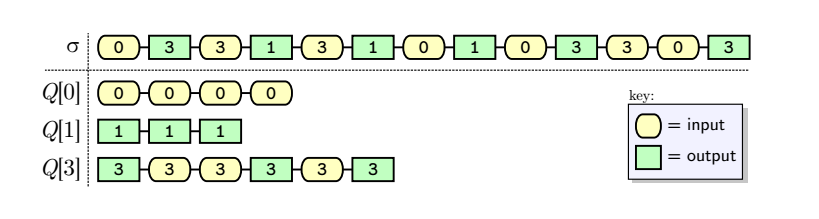
在记录阶段,Efuzz框架会构建一个按顺序的记录序列(𝜎),例如 𝜎 = [𝜎1, 𝐸, 𝜎2],其中 𝐸 是一个输入。
在模糊测试阶段,Efuzz首先重放前缀 𝜎1(作为主干的一部分),然后突变 𝐸 生成一个或多个突变体 𝐸′。接下来,用 𝐸′ 替换 𝐸 进行重放。
重放 𝐸′ 后,原本的后缀 𝜎2 可能无法继续重放,因为程序行为已经发生了偏离。这就意味着突变后的序列 𝜎′ = [𝜎1, 𝐸′, 𝜎2] 可能无法实现。
所以这里使用另一种方法来处理这种情况。作者这里引入的方法是 relaxed replay,核心思想是使用系统调用仿真去建立分叉后的执行路径。具体的方法就是,为每一个系统调用创建一个仿真例程,每一个例程将会接受系统调用参数,并且返回一个结果。同时,这些例程是可以被随时调用的。
5.1 Relaxing I/O System Call Ordering
文中介绍了一种通过 miniqueue 来解决前面提出的在变异后后续的重放问题,如上图所示,miniqueue: 这个方法将记录序列 𝜎 分成若干个 “miniqueues”(小队列),每个小队列与一个特定的I/O源(即文件描述符 fd)对应。例如,一个文件描述符对应一个队列,管理与该描述符相关的系统调用。
上面的图中,在原始的全局顺序(𝜎)下,只有来自文件描述符0的读取系统调用可以被服务。但在突变之后,程序可能会尝试在不同的文件描述符上进行I/O操作。为处理这种情况,这种方法允许根据每个 fd 的局部顺序,而不是原始的全局顺序(𝜎),直接从对应的 miniqueue 处理I/O系统调用。

对于程序来说,使用poll call来查询当前可用的 I/O操作数量也是很常见的,relaxed replay 必须使用仿真处理轮询系统调用。该算法如算法2所示,是仿真例程的具体示例。EmulatePoll 算法模拟了 poll 系统调用,通过遍历每个文件描述符的操作队列,检查是否有可以立即执行的I/O操作。如果检测到可以执行的操作,则返回检测到的数量;如果没有检测到可执行操作,算法通过重新排序操作队列来避免阻塞,并继续尝试检测。这个过程确保了即使在模拟环境中,也能尽可能模拟真实的I/O操作行为。
对于I/O调用,特别是输入和输出的顺序变化,系统通过模拟poll操作和适应突变后生成的额外输出来处理。而对于非I/O调用,系统通过模拟、传递、失败和退出等策略来处理不同类型的系统调用,以确保测试的继续进行并避免程序进入死循环。
6 IMPLEMENTATION
envfuzz 由 c++ 代码完成,总共大概有 13k 的代码量
在 record 阶段,记录所有必要的信息,如系统调用(主要部分),命令行参数,环境变量,信号,线程交错(thread interleavings),特殊的非确定性指令。为了拦截系统调用,框架采用了多种技术。通常的做法是使用静态二进制重写(static binary rewriting)技术,重写C库(libc)中的系统调用指令,将控制流引导到框架的拦截器例程中。这是通过使用E9Patch二进制重写系统来实现的。框架还会在运行时重写虚拟动态共享对象(vDSO),并使用seccomp机制生成信号(SIGSYS),以拦截C库外部的系统调用(这种情况较为少见)。没有使用ptrace机制,因此避免了在重放期间进行内核模式和用户模式之间的切换,从而优化了常见情况下的性能。
多线程程序处理
序列化系统调用(Serializing System Calls)
- 记录阶段:在程序的记录阶段,所有的系统调用都是按序列化的方式处理的。这意味着在记录阶段,程序中的多个线程不会同时运行,而是一个线程执行完毕后,另一个线程再运行。这样做是为了简化线程调度,确保系统调用的顺序是一致的且可以被正确记录。
纤程(Fibers)的使用:
- 重放与模糊测试阶段:在重放和模糊测试阶段,
Envfuzz使用了轻量级的“纤程”(fibers)来代替系统线程。纤程是一种纯用户态实现的执行线程,其上下文切换由记录的调度(𝜎)来决定。这种设计绕过了传统fork()调用中的一个主要技术限制:在fork()操作中,只有调用fork()的那个系统线程会被实际克隆,而其他线程不会被克隆。 - 纤程的优势:纤程与系统线程的不同之处在于,它们完全在用户态中实现,没有用户态与内核态的交互。因此,在重放阶段,纤程可以直接替代系统线程,并且不需要特殊处理。此外,由于纤程是在用户态中实现的,它们不会受到
fork()操作的影响,能完整地保留fork()之前的状态,这对Envfuzz的模糊测试算法是至关重要的
envFuzz 设计与反馈机制
直接作用于二进制文件:
Efuzz被设计为可以直接在二进制文件上运行,而不需要源代码。这样可以使得Envfuzz适用于更多的应用程序,而不受编程语言或开发环境的限制。
状态与分支覆盖作为反馈:
- 状态覆盖:在模糊测试过程中,
Envfuzz使用状态覆盖(state coverage)作为反馈机制。这种反馈不需要对二进制文件进行额外的插桩操作。 - 分支覆盖:分支覆盖(branch coverage)是另一个重要的反馈机制,用于检测程序在不同输入下走过的分支路径。为了收集分支覆盖的反馈信息,
Efuzz可以使用经过修改的 E9AFL 工具对二进制文件进行插桩(instrumentation)。
支持大型应用程序:
Envfuzz的实现可以记录和模糊测试大型应用程序,这表明它在实际环境中具有良好的适用性和可扩展性。
7 EVALUATION
7.1 Experiment Setup
Subject Programs
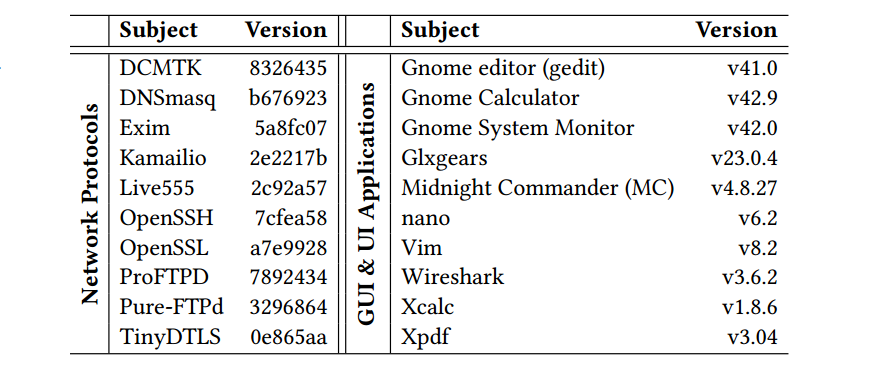
envFuzz 测试的程序主要分为两类,一类是左边的基于网络协议的程序;另外一类是右边的基于GUI的程序。对于左边程序检测 envfuzz 发现 bug 的性能,可以使用 ProFuzzBench 作为 baseline 测试。然后对于 GUI 程序几乎没有 fuzz 测试集,所以作者这里选出了几类比较知名的 linux 下的 GUI 程序。
Comparisons
对于网络协议,这里将 AFLnet 和 NYX-NET 作为 baseline 进行比较。
对于GUI程序,无。
Performance Metrics
评价 envfuzz 的性能指标,分别为 (1)bug 发现能力;(2)路径覆盖率,其中将第一个作为主要因素来考量 envfuzz 的性能。
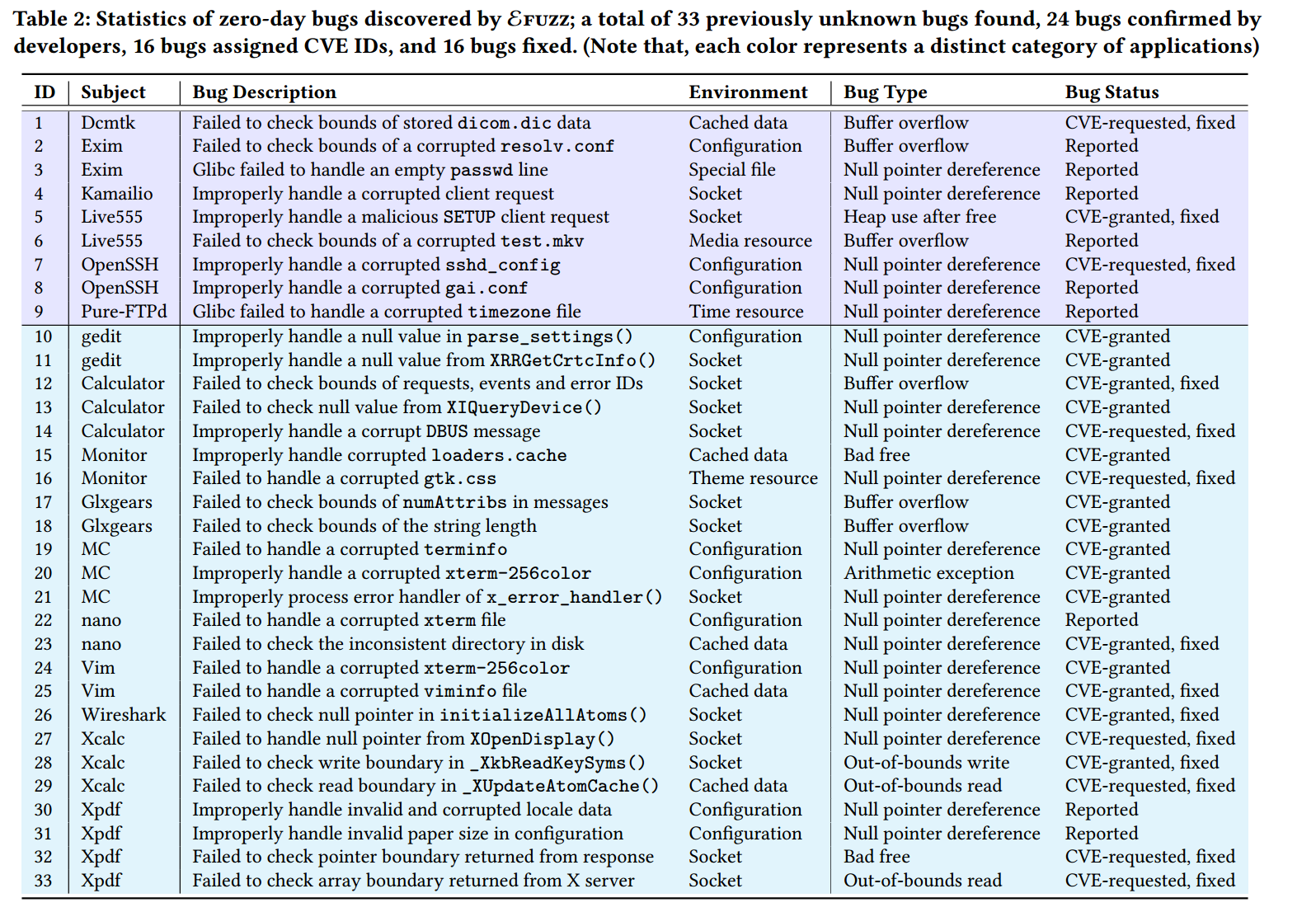
上图即为 envFuzz 最后实际检测出来的漏洞,每一个程序项目在 24 小时内完成,可以发现 envfuzz 还是非常强大的,笔者在自己机器跑的时候,也能在短时间内跑出较多的 crash。
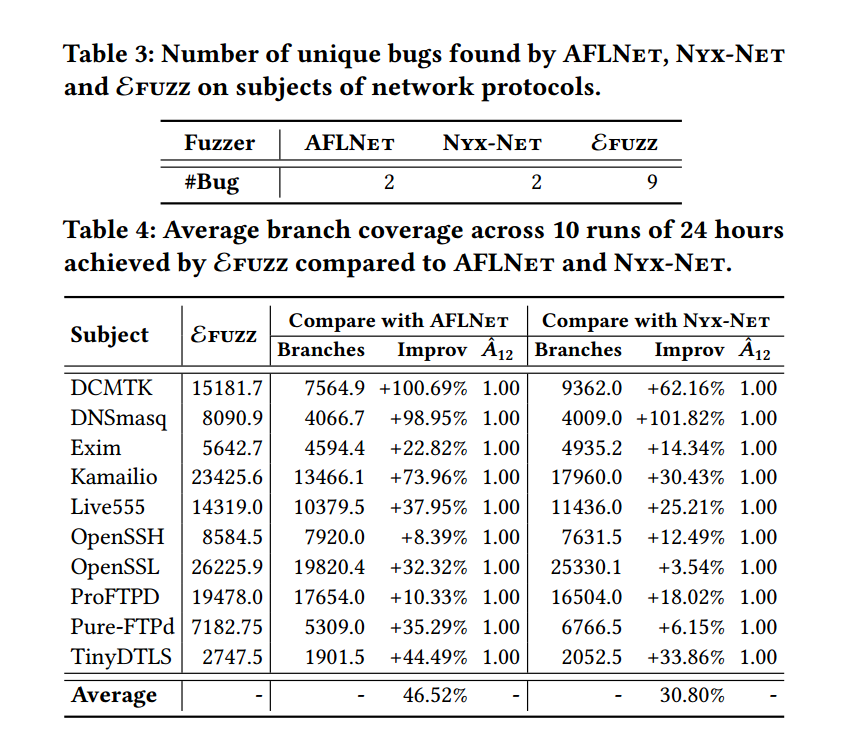
上图为 envfuzz 和 AFLnet,NYX-net 的统计数据,上图为24h内发现的 bug 数,下图为路径覆盖分支数,可以看到envfuzz的效果远远比另外两个 fuzzer 好。
总结
等我用明白了再来….
- Title: 看论文 Program Environment Fuzzing
- Author: henry
- Created at : 2024-08-10 21:14:47
- Updated at : 2024-08-21 09:40:25
- Link: https://henrymartin262.github.io/2024/08/10/envFuzz/
- License: This work is licensed under CC BY-NC-SA 4.0.