
南大《软件分析》4.0 Data Flow Analysis

课程环境:https://tai-e.pascal-lab.net/lectures.html
课程视频:https://www.bilibili.com/video/BV1b7411K7P4
南大《软件分析》4.0 Data Flow Analysis
这里介绍上一节没有介绍完的另外两个数据分析方法。
1.0 Live Variables Analysis
首先来直接看 Live variables analysis (为方便说明后文用 LVA 表示)的定义如下:

需要注意的是上面黑框中红色的部分,不同于我们之前说的 Reaching Definition analysis(RDA),在 RDA 中我们是以 Definition 为核心定义的,而这里目标换为了变量。
再来看看上面这张图,可以发现变量 v 在整个路径上没有被重新定义过,且在一点处对 v 进行了 use(v),我们就说 v 在这条路径上是 live 的。
简单来说就是想要知道这个变量值是否在后面会被使用。这个方法可以用于为变量分配寄存器的过程,设想这样一个场景,当前寄存器都在使用状态中,但此时需要加载一个新的内存值,我们需要决定覆盖哪个寄存器,这时候 LVA 就派上用处了,我们可以通过分析在某一个点 p 时,v 如果为 live 则保留其值,否则如果为 dead 则覆盖存放该值的寄存器。
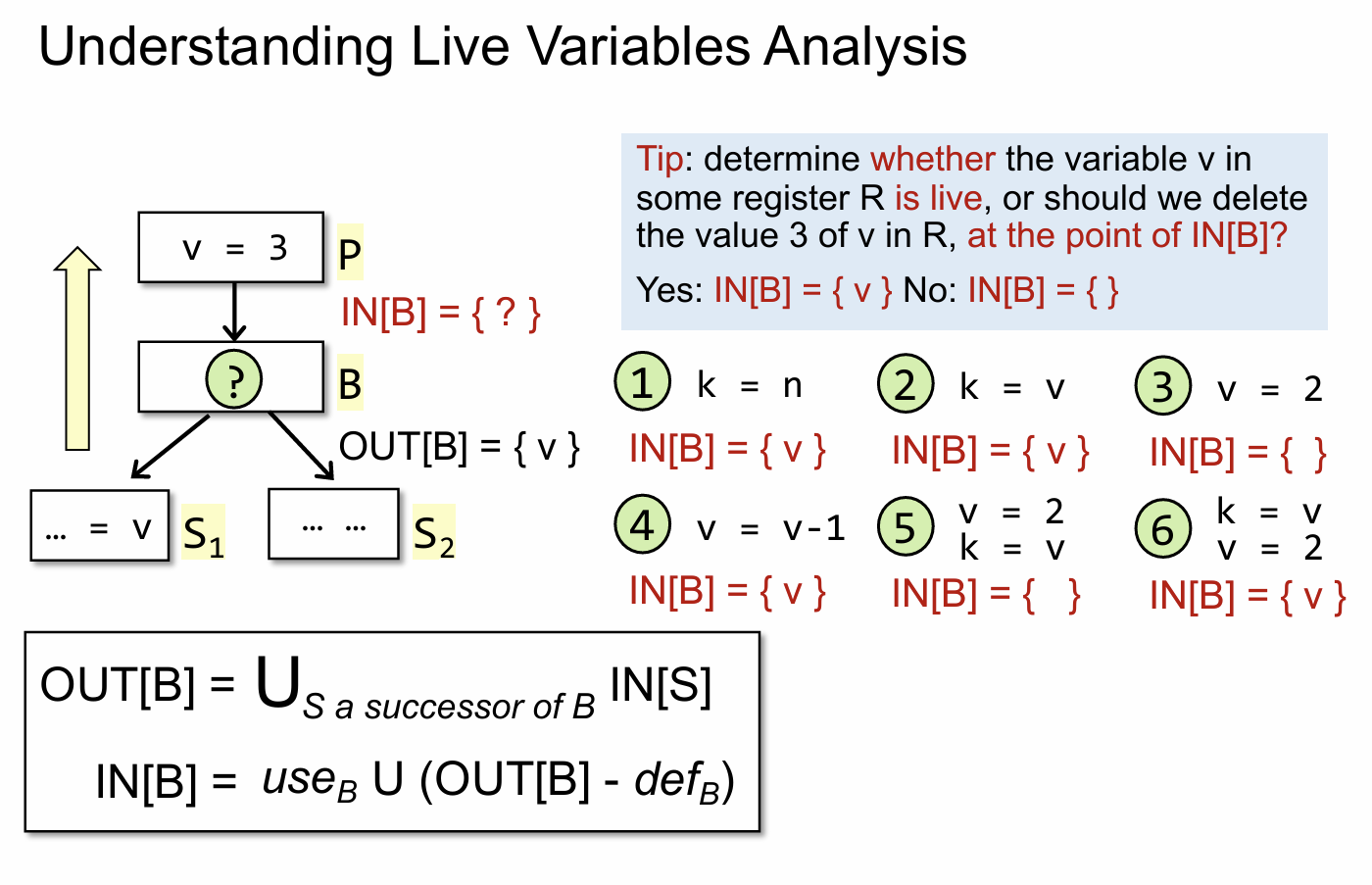
我们简单通过一些例子来说明 LVA 的具体过程,需要记住的是 LVA 是 backward analysis,就是倒着往前分析,首先 OUT[B] = {v},这是因为 S1 中有使用 v。再来看看 B 中对应不同情况时,IN[B] 的值。
| 情况 | 输出 |
|---|---|
| k = n | v 没有被 def(define),因此也就是说 v 仍然是 live 的 |
| k = v | v 被 use,但是也没有被 def,因此 v 的值仍然在这一点是 live 的 |
| v = 2 | v 被 def,OUT[B] - def = {v} - {v} = ∅ |
| v = v-1 | v 被 use 的同时也被 def,从执行的角度来思考,先计算 v-1(use),在赋值 v(def),由于是 backward analysis(重要),所以 IN[B] = {v} |
| v = 2 k = v | 对于这个情况我们可以分为两步完成,LVA 会先看到 k = v(第二种情况),执行完的结果是 OUT[B] = {v},再来看 v = 2(第三种情况),执行完最后的结果是 IN[B] = {} |
| k = v v = 2 | 跟上面的分析方法,同理,倒着一步一步来就可以了 |
接下来是 LVA 的算法实现部分

需要好好理解这一部分,对每一步(每一个运算)都要理解其含义,不仅如此可以结合后面的练习,来体验这个算法的过程。
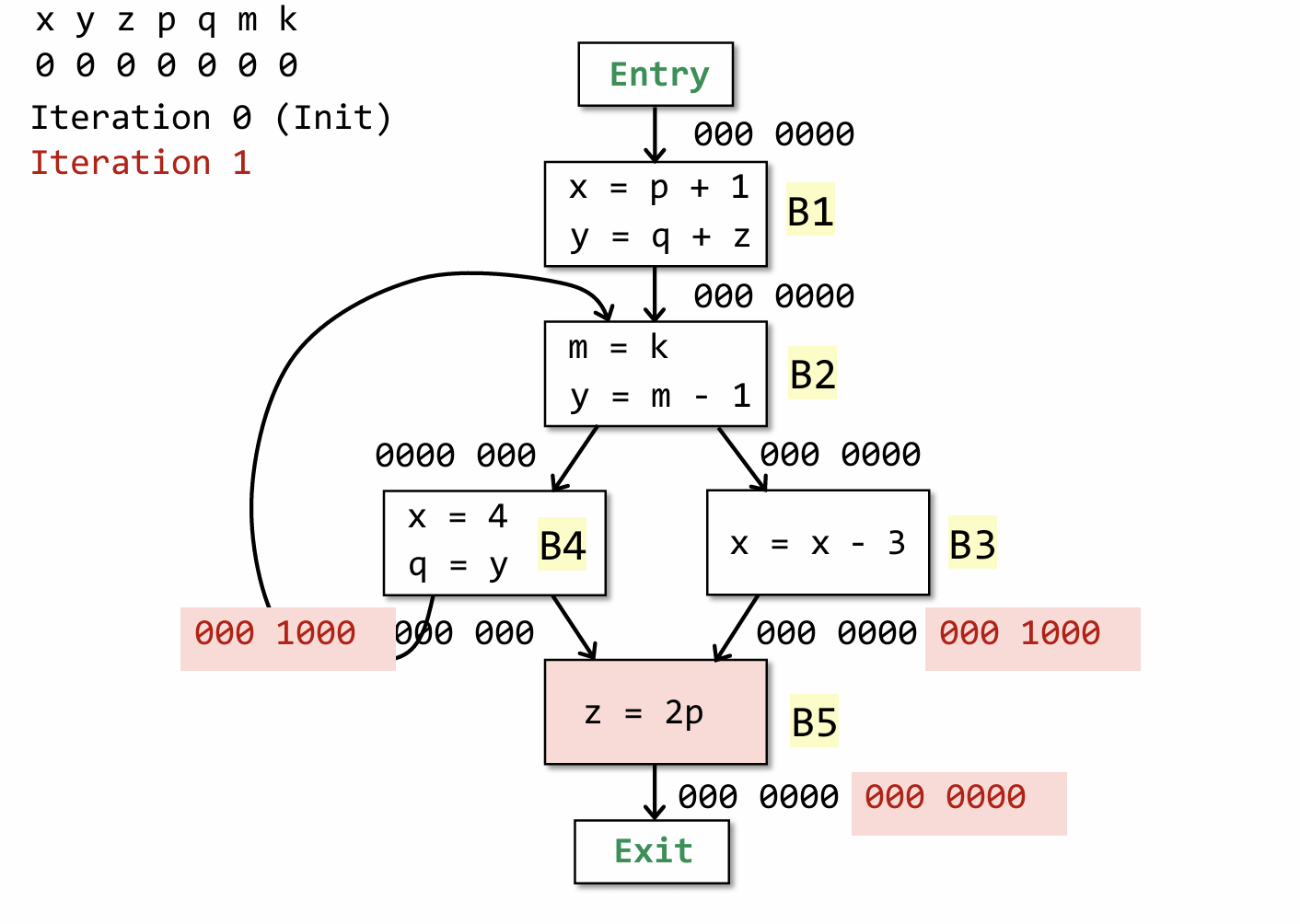
这是一个初始状态,从后面开始依次分析,z = 2p,p 被 use ,因此其对应位设置为1,z 被重定义,且由于z对应的位置已经是dead,故也还是0,最后的结果 IN[B] = 000 1000。
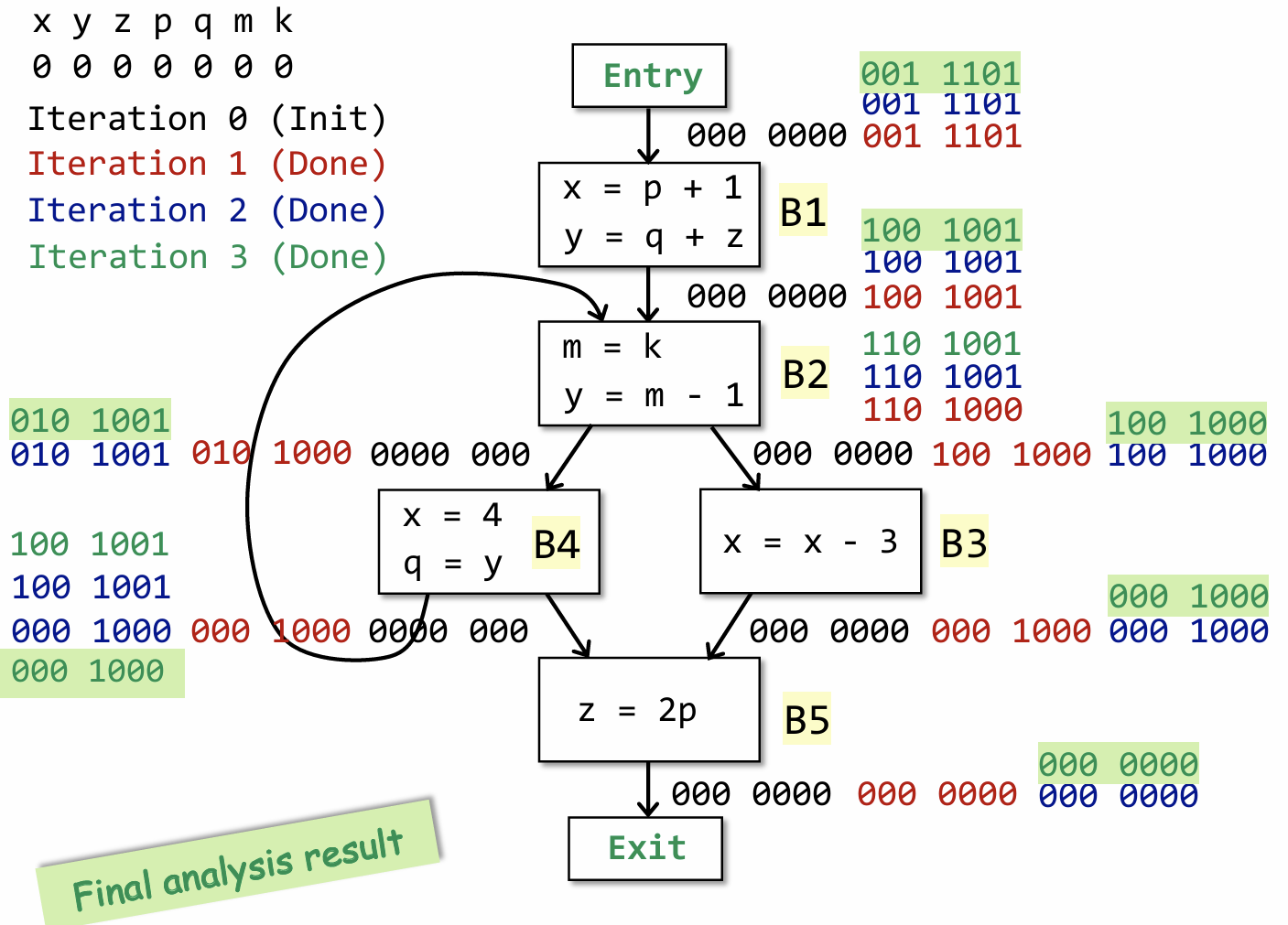
最后整个过程迭代完的结果如上所示,如果可以把上面所有的过程都自己手算一遍,相信你一定可以完全理解 LVA 的算法。(笑)
总结
我认为对于 LVA,需要重点掌握的是它抽象的对象是变量。其次它是一个 may analysis,什么意思呢,就是说只要后面存在一条路径满足 LVA 的条件,我就认为这个变量是 live 的,这一点在公式中具体体现为 U 操作。另外一个就是它是一个 backward analysis,就是从后往前分析,这其实跟我们分析的问题有关,因为我们研究的是一个变量在后面的过程中是否 live。
需要注意的是,其实也可以使用 forward analysis,只不过这里来说 backward 更方便
2.0 Available Expressions Analysis

首先还是直接来看定义,还是比较抽象的一个东西,大概的意思就是说从 entry 到 p 的所有路径都必须经过 x op y 的测试,这里的测试就指的是 x 和 y 当中任意一个变量在这个过程中没有被重新定义。
实际上 Available Expressions Analysis (AEA)可以被拿来用作编译优化,因为试想如果一个表达式的值在后面会被经常使用到,那我们可以直接用一个临时变量计算出它的值,然后后面直接用临时变量来在进行其他运算。
注意事项:在 AEA 中,我们需要抽象的对象是 x op y,且根据其定义,不难理解其实一个 must analysis,因为 AEA 要求的是所有路径都必须满足特定的条件
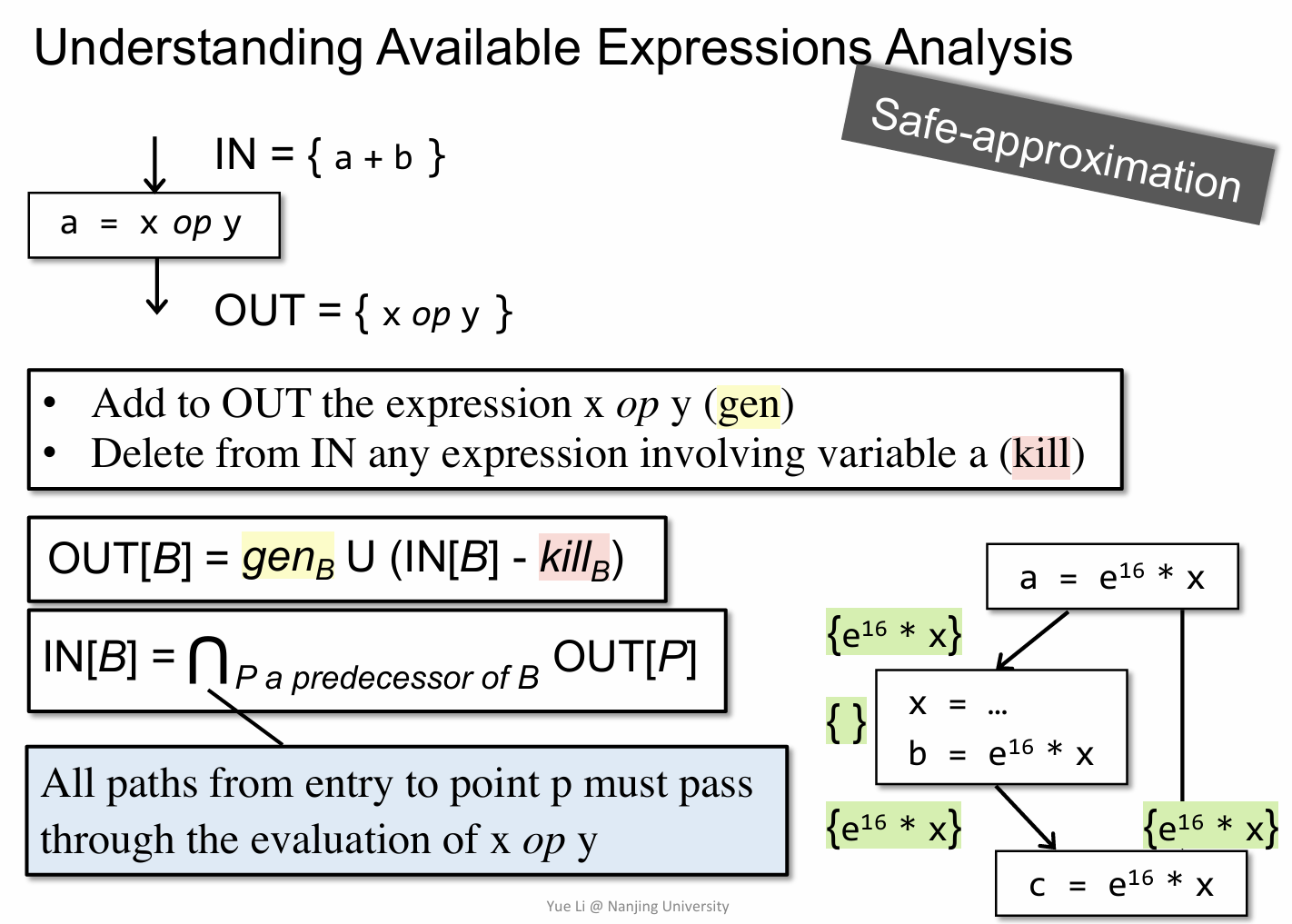
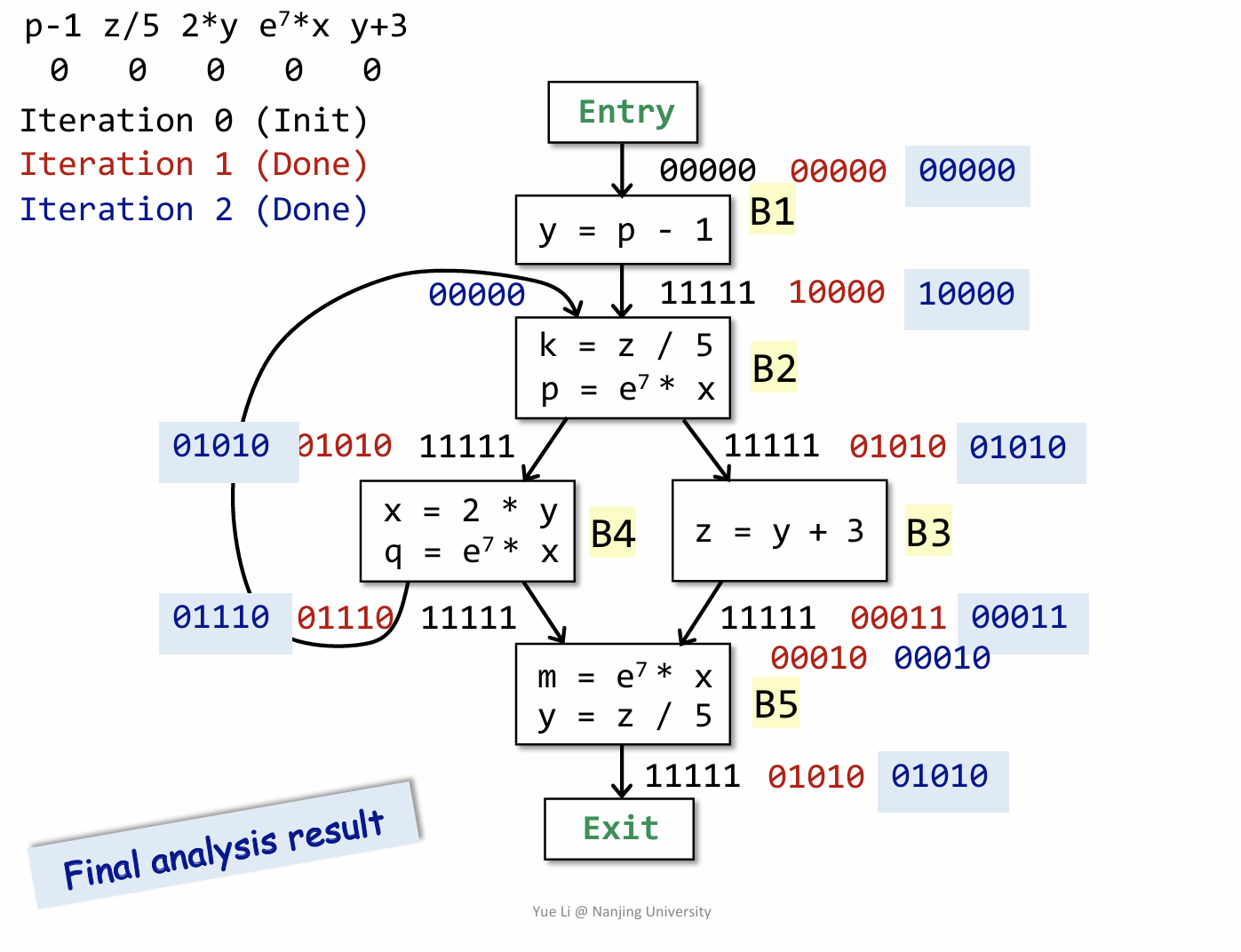
这里也是给出了一个简单的例子用来理解 AEA 的过程,关键在于理解 gen 和 kill 是如何产生的,然后就套用公式得到输出。需要注意的是不同于 RDA 和 LVA,AEA 在计算 IN[B] 时是一个交集操作(体现在要所有路径都满足条件)。
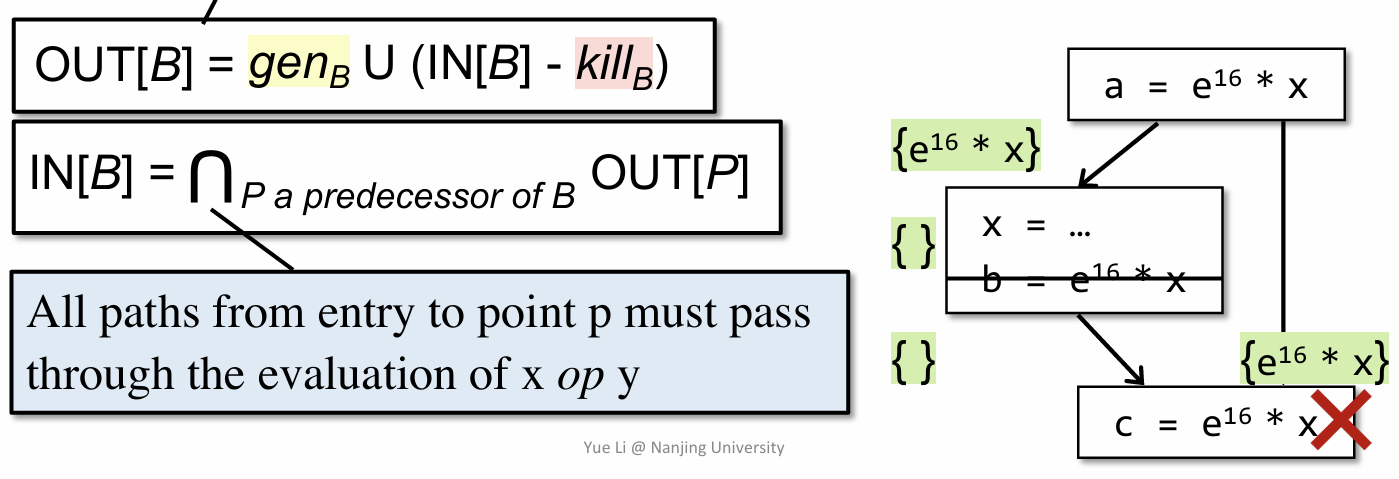
因此像上面这个例子中时,最后的交集之后,结果就为空,AEA 的完整算法如下。

值得注意的是初始化过程中的 OUT[B] = U,从直观上理解就是认为这些表达式值都是可用的。
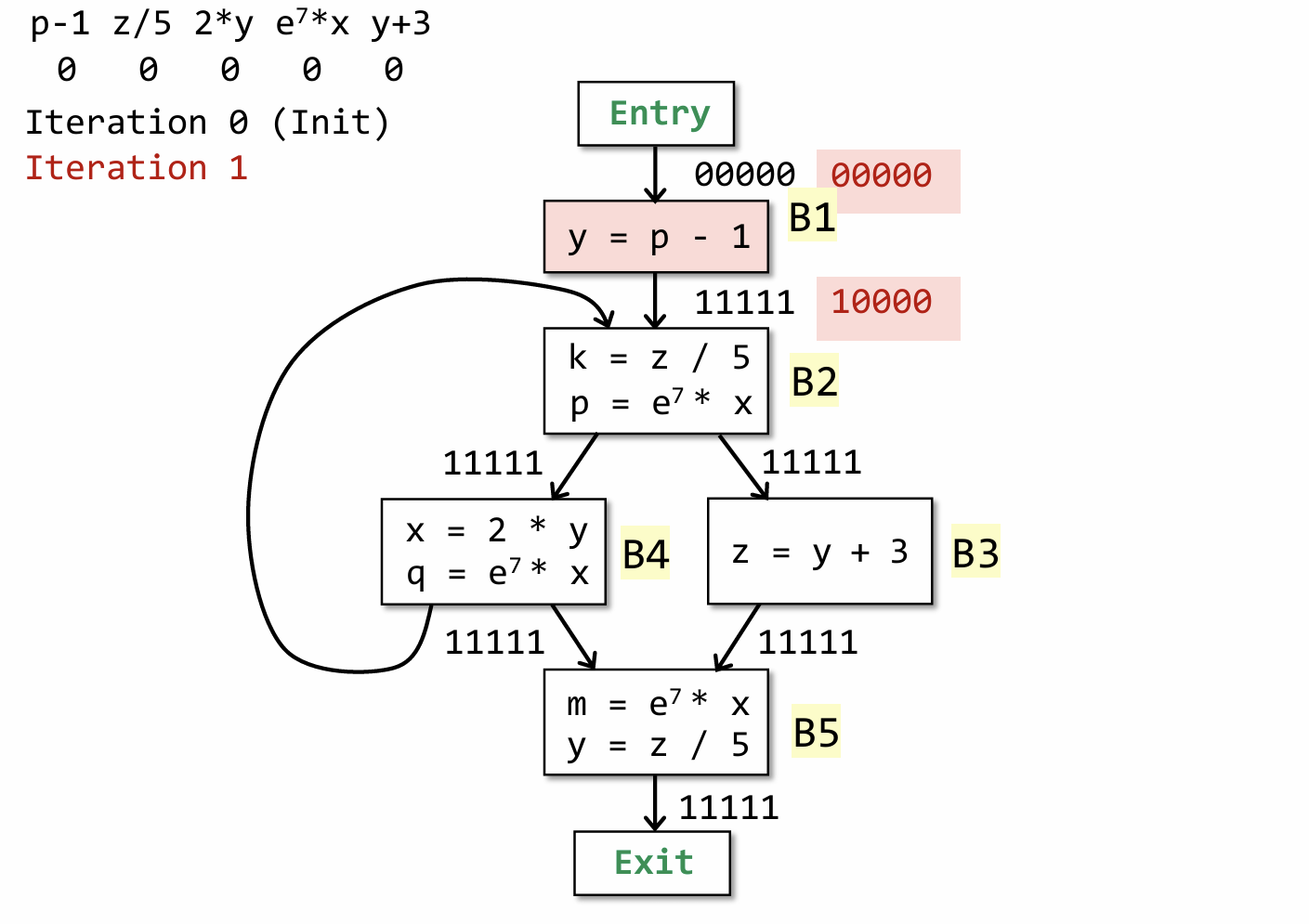
对于 B1 来说,
总结
和 LVA 一样,对于 AEA,需要重点掌握的是它抽象的对象是表达式。其次它是一个 must analysis,什么意思呢,就是说每条路径都要满足 AEA 的条件,这一点在公式中具体体现为 ∩ 操作。另外一个就是它是一个 forward analysis,这一点在前面的计算过程中有所体现。
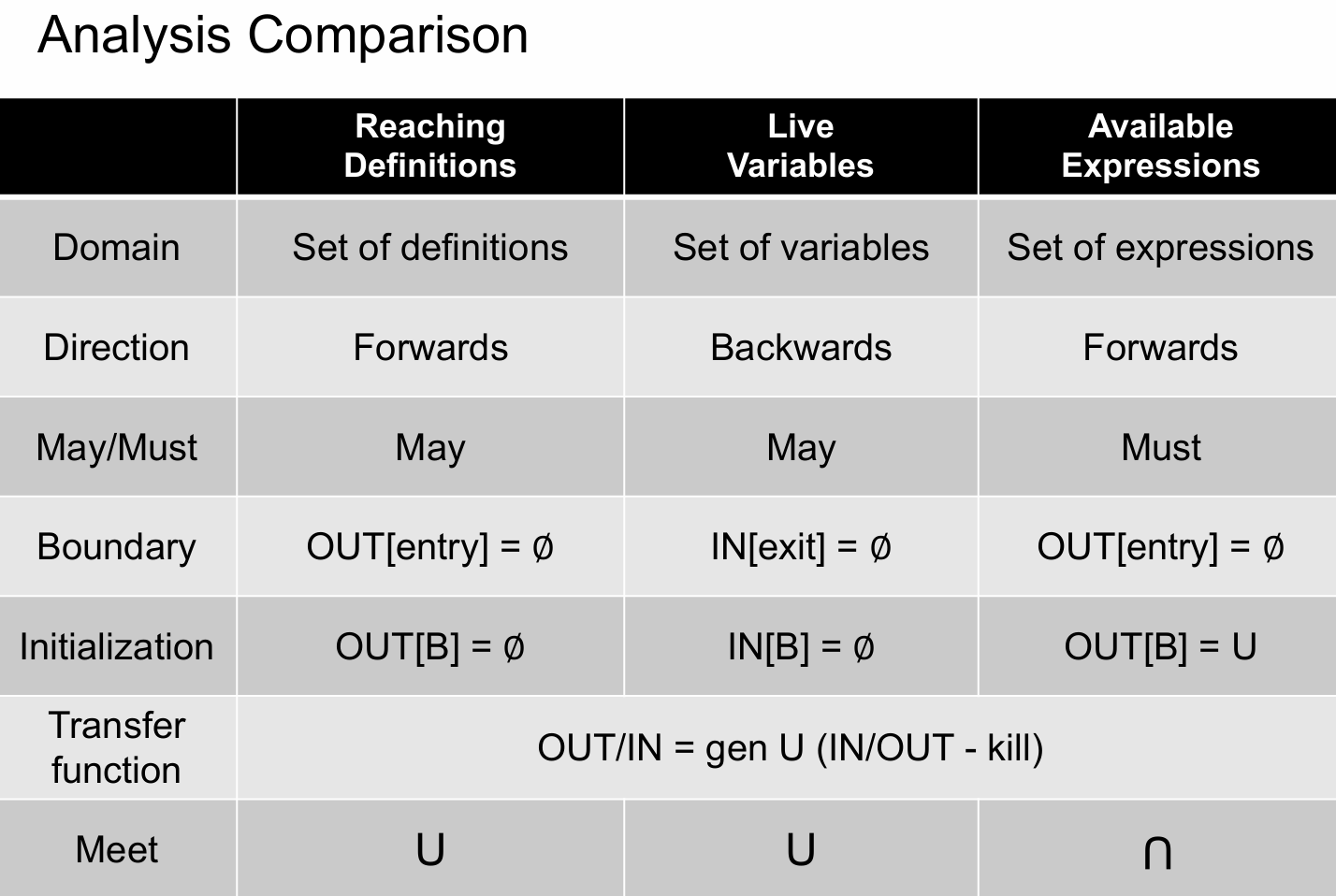
3.0 三种分析方法对比
实际上这三种方法,我个人认为如果是初学的话还是比较容易混淆的(比如我),一些方法就是可以结合具体的实际使用案例来帮助理解这三种分析方法,下面是三种分析方法老师总结的表格(非常重要),对我们理解这三种分析方法的共同点和不同点很有帮助。
思考题

- Title: 南大《软件分析》4.0 Data Flow Analysis
- Author: henry
- Created at : 2024-08-06 17:11:02
- Updated at : 2024-08-06 17:13:11
- Link: https://henrymartin262.github.io/2024/08/06/4.0_Data_Flow_Analysis/
- License: This work is licensed under CC BY-NC-SA 4.0.