
LLVM ebpf 汇编学习

Reference
https://arthurchiao.art/blog/ebpf-assembly-with-llvm-zh/
LLVM eBPF 汇编编程学习
介绍
学习基于 LLVM eBPF 汇编开发 BPF 程序,之所以不用C,而用汇编的理由如下:
- 测试特定的 eBPF 指令流
- 对程序的某个特定部分进行深度调优
由于直接从字节码写程序非常耗时,所以Clang/LLVM 为 ebpf 提供了一个编译后端,能从C 源码直接生成 ebpf 字节码(GCC 也可以但是没有 clang/llvm 完善)。
几种 eBPF 汇编编程的方式:
- 直接编写 eBPF 字节码程序。也就是编写可直接加载运行的 二进制 eBPF 程序(对开发者不友好)
- 直接用 eBPF 汇编语言编写,然后用专门的汇编器 (例如
ebpf_asm)将其汇编(assemble)成字节码。 - 用 LLVM 将 C 编译成 eBPF 汇编,然后手动修改生成的汇编程序, 最后再将其汇编(assemble)成字节码放到对象文件。
- 在 C 中插入内联汇编,然后统一用 clang/llvm 编译。
上述四种方式 clang/llvm 都支持,这里介绍第三种和第四种
Clang/LLVM 编译 eBPF
bpf.c 内容如下:
1 | cat bpf.c |
编译成为 eBPF 程序
1 | # 注意 target 类型指定为 `bpf` |
复杂的程序使用下面的命令编译
1 | $ clang -O2 -emit-llvm -c bpf.c -o - | \ |
以上命令会将 C 源码编译成字节码,然后生成一个 ELF 格式的目标文件
查看elf文件中的eBPF字节码

0xb7000000:r0=0
0x95000000:exit return r0
ebpf 汇编语法参考文档
C 生成 eBPF 汇编 + 手工修改
还是使用前面的 bpf.c 文件
将 C 编译成 eBPF 汇编(clang)
注意这里 -target 目标需要设置为 bpf,不然就会按默认方式生成汇编
1 | clang -target bpf -S -o bpf.s bpf.c |
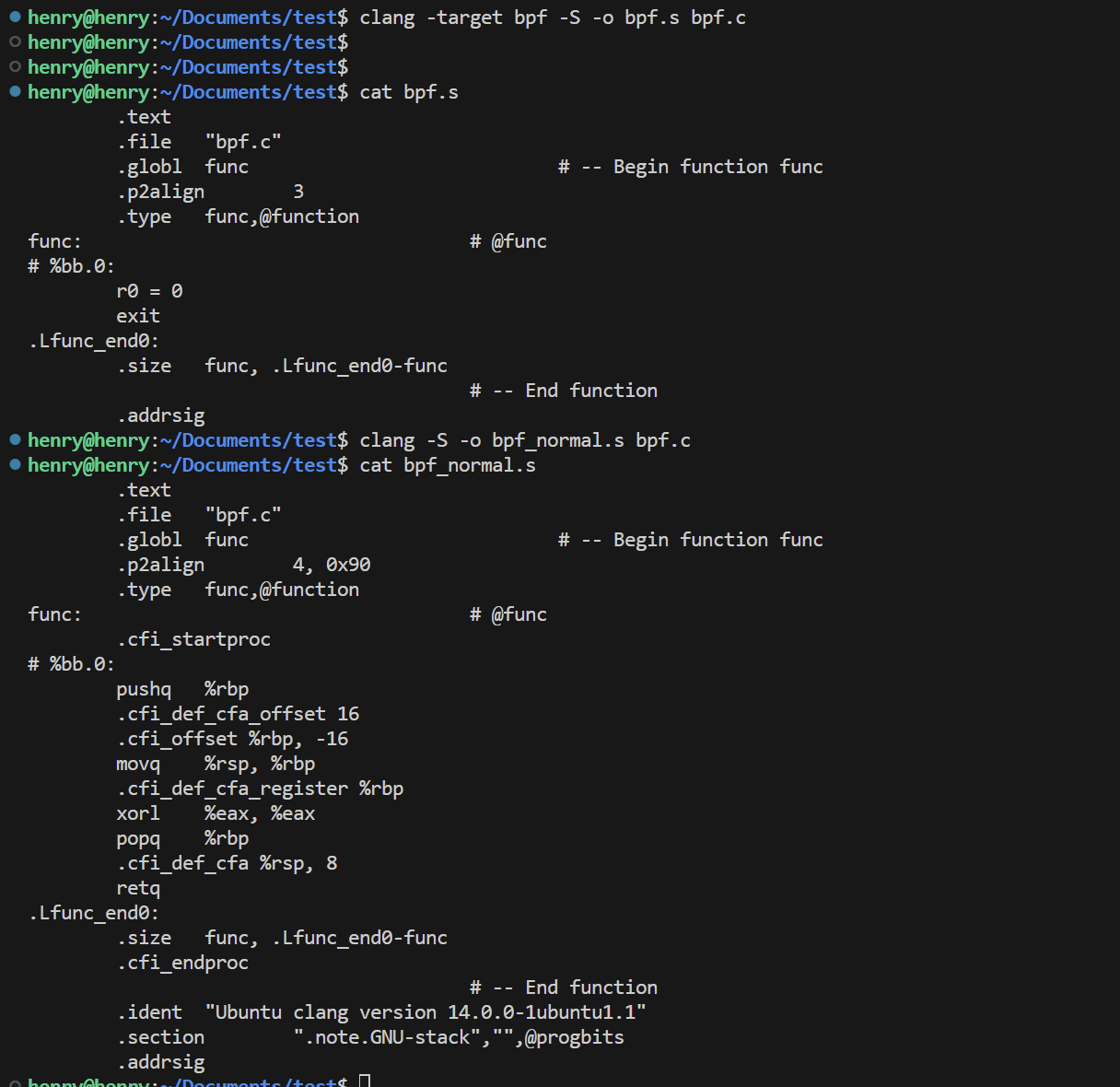
从上图可以清晰的看到两种编译方式,生成的汇编代码语法是不相同的。
手动修改 ebpf 汇编
我们在生成的 ebpf 汇编程序中加一行指令r0 = 3

将汇编程序 assemble 成 ELF 对象文件(llvm-mc)
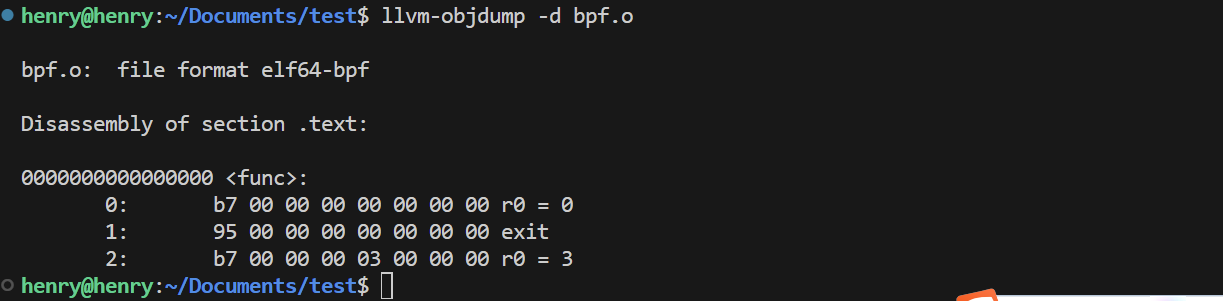
1 | llvm-mc -triple bpf -filetype=obj -o bpf.o bpf.s |
这一步将 ebpf 汇编文件生成了 ebpf 字节码文件,可以看到相较于前面的一行,这里多出来一行,即是我们添加的r0 =3 这一行命令
1 | henry@henry:~/Documents/test$ readelf -x .text bpf.o |
变换成为可读的方式查看 ebpf 字节码
当然上面的16进制的字节码并不好看,llvm_objdump 支持查看 ebpf 字节码程序
1 | # -d : alias for --disassemble |
编译时嵌入调试符号或C源码
LLVM 还可以将调试信息嵌入到字节码文件当中,需要在 clang 编译时加上 -g 参数
1 | # -g: generate debug information. |
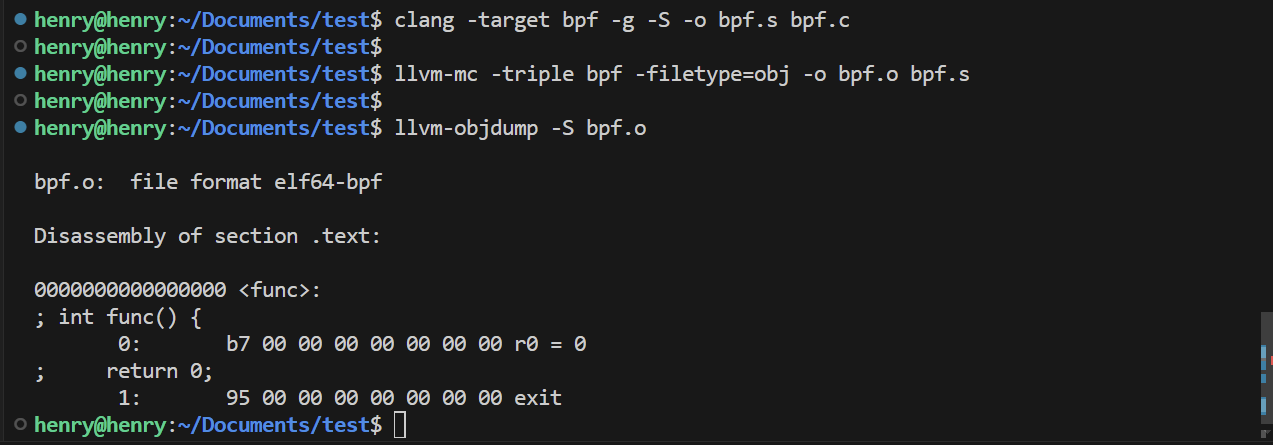
注意事项:用的是 -S(显示源码),不是 -d(反汇编)。
内联汇编
另一种生成和编译 eBPF 汇编的方式:直接在 C 程序中嵌入 eBPF 汇编。
示例
1 | int func() { |
对于上述内联汇编的解释如下(GPT回答):
在 GCC 的内联汇编语法中,输出操作数、输入操作数和修饰符(即约束)的位置和顺序是固定的,这使得我们可以确定 %0、%1 等占位符所对应的具体操作数。以下是这些部分的具体规则:
- 输出操作数(Output Operands):位于冒号
:之后的第一组,括在双引号""中,并以等号=开头的表示输出操作数。输出操作数的约束通常以=开头,表示这是一个输出(即目标)操作数。 - 输入操作数(Input Operands):位于输出操作数之后的第二组,括在双引号
""中,不以等号=开头的表示输入操作数。
在内联汇编代码中,操作数列表中的位置决定了占位符 %0、%1 等所引用的具体操作数。下面是对应关系的一个例子:
1 | asm ("<汇编代码>" : <输出操作数列表> : <输入操作数列表>); |
- %0 对应输出操作数列表中的第一个操作数。
- %1 对应输入操作数列表中的第一个操作数。
- %2 对应输入操作数列表中的第二个操作数,依此类推。
在上面 c 代码中:
1 | asm ("lock *(u64 *)(%0+0) += %1" |
- %0 对应第一个输出操作数
"=r"(foobar_addr)。 - %1 对应第一个输入操作数
"r"(r3)。
因此,%0 引用了第一个输出操作数 foobar_addr,因为它是在输出操作数列表中的第一个位置上。
编译生成的字节码文件
1 | clang -target bpf -Wall -O2 -c inline_asm.c -o inline_asm.o |
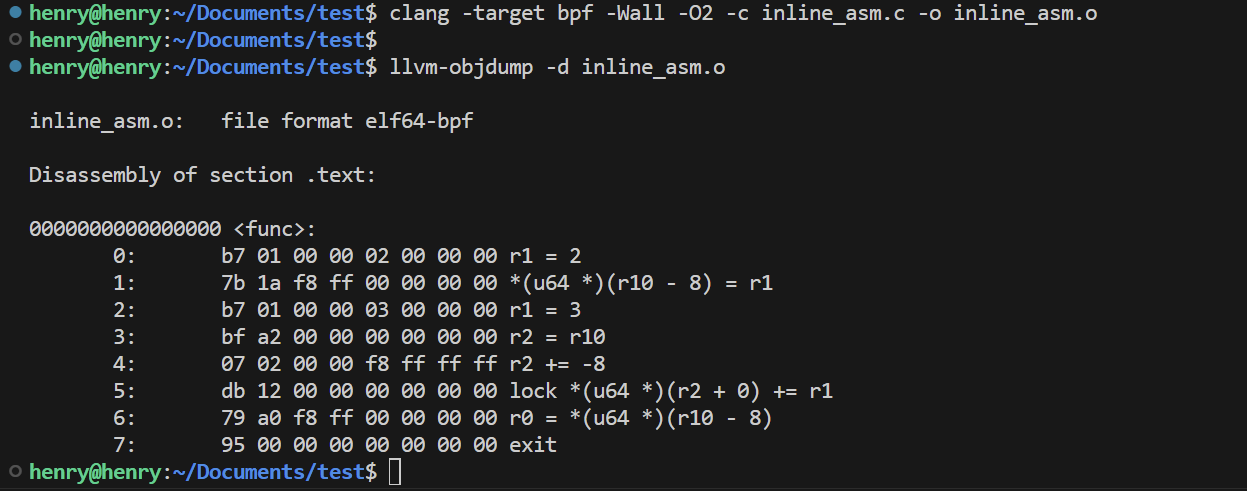
这种方式无需像前一种需要将编译和汇编步骤分开
总结
前面两种方式最后都可以成功生成 ebpf 字节码文件,但不一定能通过 ebpf verifier 的检查。
- Title: LLVM ebpf 汇编学习
- Author: henry
- Created at : 2024-07-29 11:37:35
- Updated at : 2024-07-29 11:45:48
- Link: https://henrymartin262.github.io/2024/07/29/llvm_ebpf/
- License: This work is licensed under CC BY-NC-SA 4.0.