
看论文 Fuzz4All Universal Fuzzing with Large Language Models

Fuzz4All: Universal Fuzzing with Large Language Models
论文链接:https://arxiv.org/pdf/2308.04748
开源代码:https://github.com/fuzz4all/fuzz4all
1. INTRODUCTION
本文针对的是对以编程语言或形式语言作为输入的系统(编译器,运行引擎,约束求解器)进行有效 fuzz 而提出的一种模糊测试模型,之所以针对这类系统进行模糊测试,是因为它们的 bug 会严重影响一些下游产品的安全性。
传统的 fuzzer 可以被归类为基于生成的和基于变异的,但这种传统的模糊测试技巧面临以下限制和挑战:
目标系统和语言的紧耦合
比如说针对某种语言的模糊测试器,放到另外一种语言下就不能再使用了
缺乏对新特性的支持
比如说传统模糊测试器只针对某种语言的某一个版本,而语言也是慢慢更新的,但这些模糊测试器并没有将这些更新的新特性加入到模糊测试器的考虑范围之内
受限的生成能力
基于生成的模糊器其通常非常依赖输入语法和一些语义规则来确保输入的有效性,但这在一定程度上会回避一些难以建模的语言特征,这使得只覆盖到语言的部分特性,基于变异的模糊器也是如此
这篇论文的工作在于:提出了一个可以针对不同语言输入(C,C++,GO)和这些语言不同的特征都能够有效进行模糊测试的基于 LLM 的模糊器。这个可以很好解决上面提出的三个问题,同时这篇文章做出的贡献在于:
- 利用 LLM 生成广泛有意义的输入进行测试
- 通过自动将用户输入提取为有效生成SUT输入的 prompt
- 迭代修改 prompt,连续生成新的模糊输入
- 在真实世界的有效性
2. BACKGROUND AND RELATED WORK
与传统的 autoprompt 和基于代理的方法不同,论文中的 autoprompt 策略直接使用GPT4合成提示,并根据特定的模糊目标对提示进行评分。
作者在这一部分提到了一些常见的模糊器,如 AFL,libfuzzer 并说明了这些模糊器由于受限的变异能力,并不能很好的生成有效输入,从而限制了新的路径的发现。PolyGlot 是一种与语言无关的模糊器,由于它有限的变异能力,还是达不到特定于某种语言设计的 fuzzer 覆盖水平。
不同于其它的 LLM fuzzers,Fuzz4All还支持生成专注于选定特性的代码片段用于目标模糊测试,简单来说支持针对多个 SUT(测试系统 system under test)的模糊测试。
3. FUZZ4ALL APPROACH
如下图所示,Fuzz4All 建立在两个模型之上,一是减少给定用户输入的 DLLM(distillation LLM),另一个是创建模糊输入的 GLLM (generation LLM)。
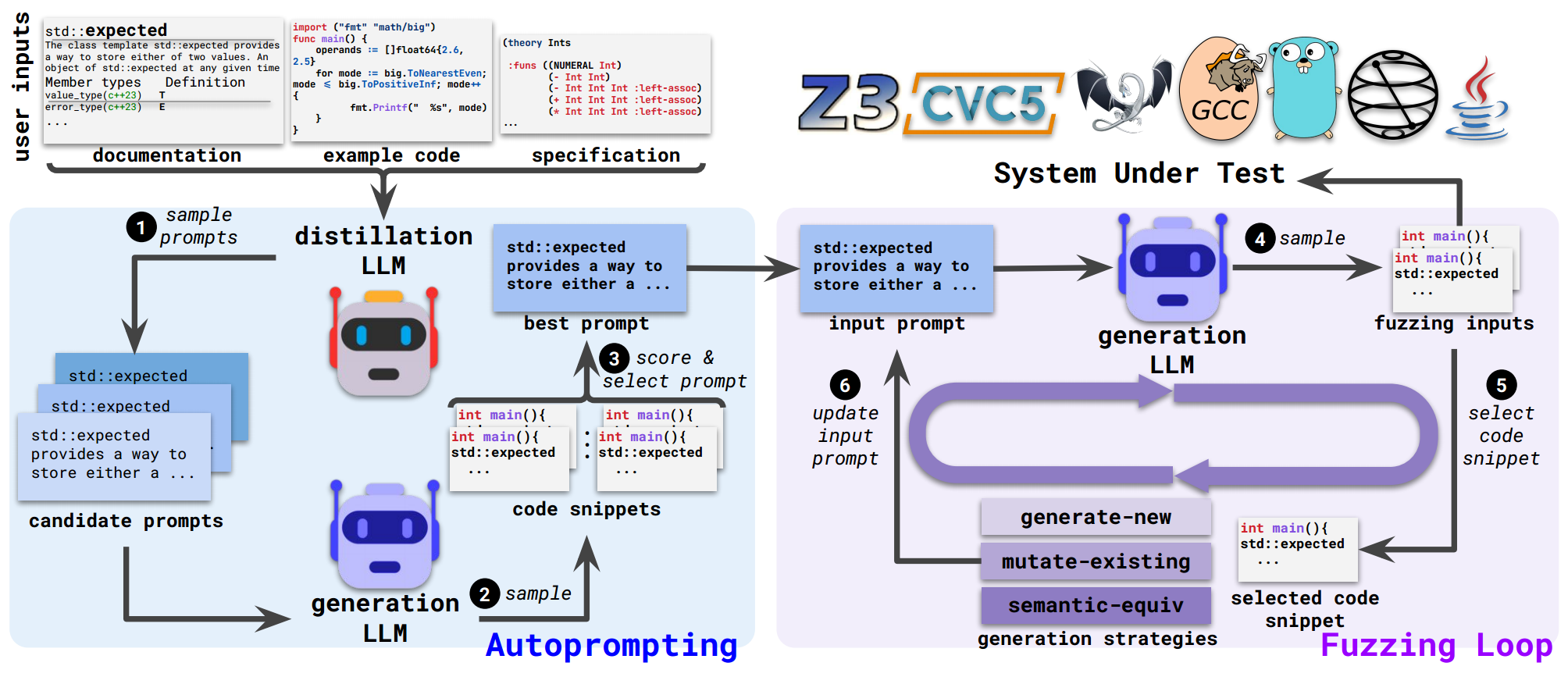
Fuzz4All通过使用大型的、最先进的DLLM 对多个不同的 candidate prompts 进行采样来执行 Autoprompting 步骤,每个 candidate prompts 被传递给GLLM以生成代码片段,从生成的代码片段中进行评分,并选出 best prompt,该 best prompt 会作为下一阶段 Fuzzing Loop 的 input prompt,这一阶段不断通过 generation LLM 生成模糊测试的有效输入,同时为了避免输出相同的输入示例,Fuzz4All 每次迭代的过程中都会更新 input prompt 来保证在下一个循环阶段,生成不一样的输入示例。
3.1 Autoprompting
从前面的图可以看到,distillation LLM 接受技术文档,示例代码,包括代码规范作为输入,不像传统的fuzzers那样要求特定的输入格式,同时由于用户输入的一些信息可能是冗余的或者不相关的,所以 autoprompting 的目标正是剔除这些影响因素,生成有效的基于 llm 模糊测试的 input prompt。

上图为 Autoprompting 实现的主要的一个算法逻辑,算法的实现思想也很简单,最终返回一个 input prompt,这里的 $M_D$ 可以理解为是 distillation LLM,Fuzz4All 首先使用温度为0的贪婪采样生成一个 candidate prompt,该算法通过低温先采样,得到具有高置信度的可信解,然后,算法继续在更高的温度下进行采样,以获得更多样化的 prompt。
在经过 distllation LLM 的处理后,会生成多个 candidate prompts,为了评估这些 prompt 的有效性和表现,这里使用 generation LLM 生成对应这些 prompt 的代码片段,然后会对这些代码片段进行评分,从而选出最优的 prompt 用于下一阶段的训练。评分的依据可以是覆盖率,发现的bug数,或者生成的输入示例的复杂性,$M_G$ 可以理解为是 generation LLM,负责选出最终计算出来的最高分的 input prompt。
3.2 Fuzzing Loop
这一步需要以前一步最后生成的的 input prompt 作为输入,并且该阶段的目标是通过 GLLM(gneration LLM)去产生足够多样化的模糊测试输入示例。但碍于 LLMs 的概率本质,对同样的输入多次采样可能会生成相同或者相似的代码片段,为了避免这一问题论文中采用示例代码片段和自然语言指令来引导生成多样化的代码片段。
模糊测试循环的高级思想是通过从先前的迭代中选择一个示例模糊测试输入并指定生成策略,不断地增加原始 input prompt。生成策略被设计为关于如何处理所提供的代码示例的指令,这些策略受到传统模糊器的启发,比如基于生成的模糊测试和基于变体的模糊测试。
在每次新的模糊循环迭代之前,Fuzz4All将一个示例和生成策略附加到输入提示符中,使GLLM能够不断地创建新的模糊输入。
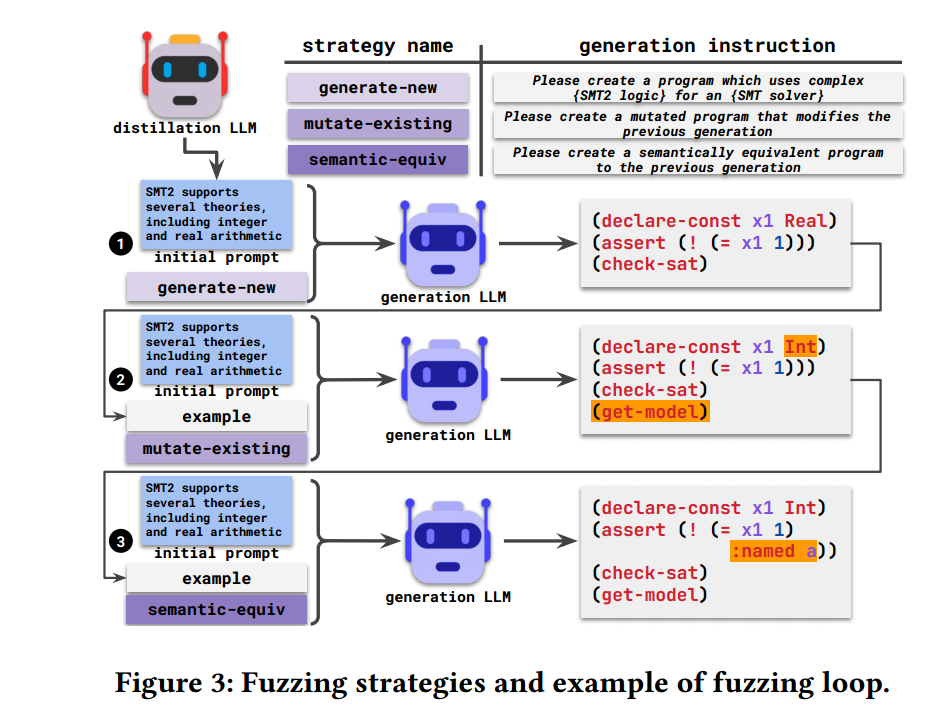
可以从上图理解整个 fuzzing loop 所做的事,其实归纳为三个核心点就是:
generate-new
通过 initial prompt 和 generate-new 指令,让 GLLM 生成一个代码片段示例,该示例作为下一个步骤的 example
mutate-existing
这一步将上一步产生的 example 进行变异(其它输入都没有变化),然后交给 GLLM 再次生成变异后的代码片段
semantic-equiv
这一步顾名思义在前一步代码示例的基础上,生意在语法上等价的另外一种代码片段,比如在上面的例子中多了个
:named a,虽然在语法上是等价的,但在找 bug 时,这种替换却是有效的

上述算法即为 Fuzzing loop 整个过程的伪代码实现,$M_G$ 即代表 GLLM,首先初始化一个 genStrats 的向量,里面分别定义了三种策略,其次第三行生成第一批原始模糊测试示例。第5行到第9行是 fuzzing loop 的主要部分,第6行会从先前产生的所有输入示例中随机选择示例用来测试,同时,第7行又从 genStrats 的三种策略中随机选择一种作为 GLLM 的下一步输入(第8行)。如果用户定义的oracle识别出意外的行为,例如,崩溃,那么算法将向检测到的错误集合添加一个(第9行)。最后,循环的终止条件设置为了耗尽所有 fuzzing budget 时停止。
Oracle
上述伪代码中有一个 Oracle,这个函数实际上是根据输入示例,来检查对应的 SUT 的行为以检测错误,这个 Oracle 可以是由用户定义,比如说我们可以将分段错误和内部断言失败作为定义 Oracle 检测错误的标准。
4. EXPERIMENTAL DESIGN
4.1 Implementation
Fuzz4All主要由python实现,与传统的fuzzers(如Csmith (>80K LoC))相比,Fuzz4All具有非常轻量级的实现。由前面的内容介绍可以知道,Fuzz4All 实际上由两个关键阶段构成即 Autoprompting 和 Fuzzing Loop,而这两个阶段的核心构成组件为 DLLM 和 GLLM。
Fuzz4All 使用 GPT4 作为 DLLM 来执行 Autoprompting,因为该模型对于广泛的基于nlp的推理任务来说是最先进的。对于 Fuzzing Loop,使用 StarCoder 模型的 hug Face 实现作为 GLLM。
4.2 Systems Under Test and Baselines
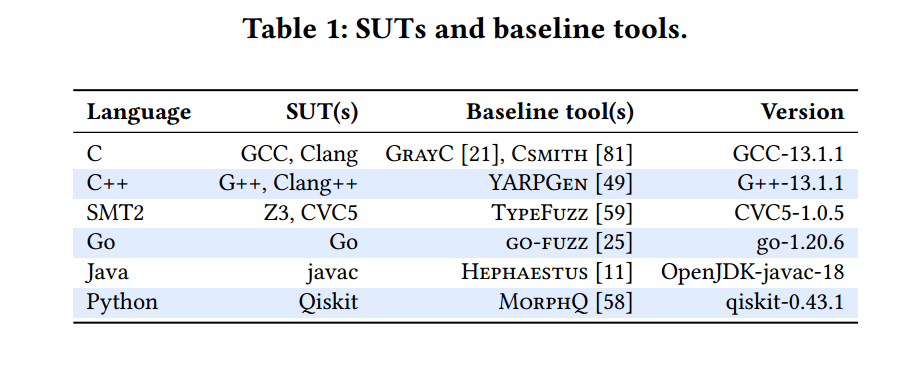
上图显示了不同的测试对象,如 GCC,Clang,同时作为对比还有一些 Baseline 工具,如 CSMITH,这是针对 C 编译器而实现的一种模糊器。
5. RESULTS
5.1 RQ1: Comparison against Existing Fuzzers
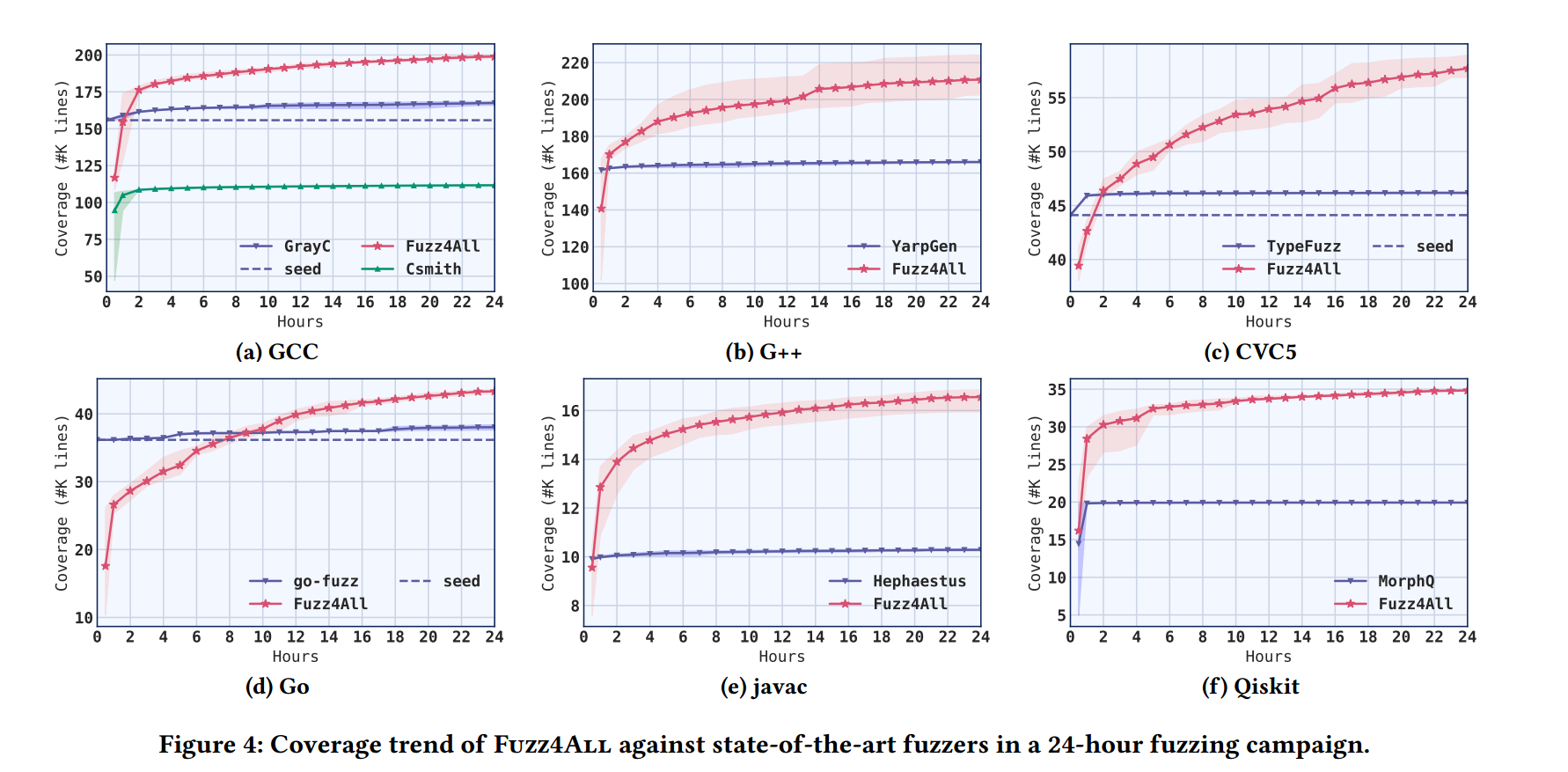
在模糊测试中覆盖路径是用来衡量模糊测试效果非常重要的一个指标,上图即反映了 24h 内 Fuzz4All 和其他对比模糊器的覆盖路径情况,其实还是可以明显看出 Fuzz4All 的覆盖路径表现还是非常不错的相较于其它几个,并且一直在保持着上升的状态,而其他几个模糊器似乎在经过短暂一段时间之后,覆盖率逐渐平稳不在升高。
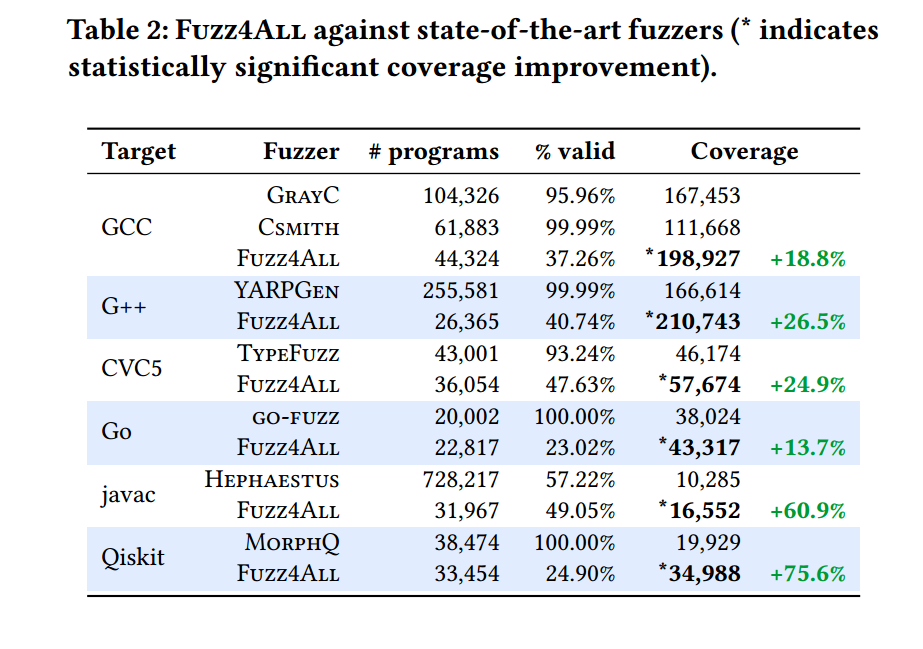
上图就明显的反映了覆盖路径提升的一个具体效果,从个人观点来看,这个确实可以理解为 Fuzz4All 的一个优势,但从上图中可以看到实际上 Fuzz4All 生成的有效输入(valid)并不高,而且显著低于其他模糊器。
5.2 RQ2: Effectiveness of Targeted Fuzzing
下表通过命中率和覆盖路径来作为衡量 Fuzz4All 在针对目标模糊测试时的有效性。
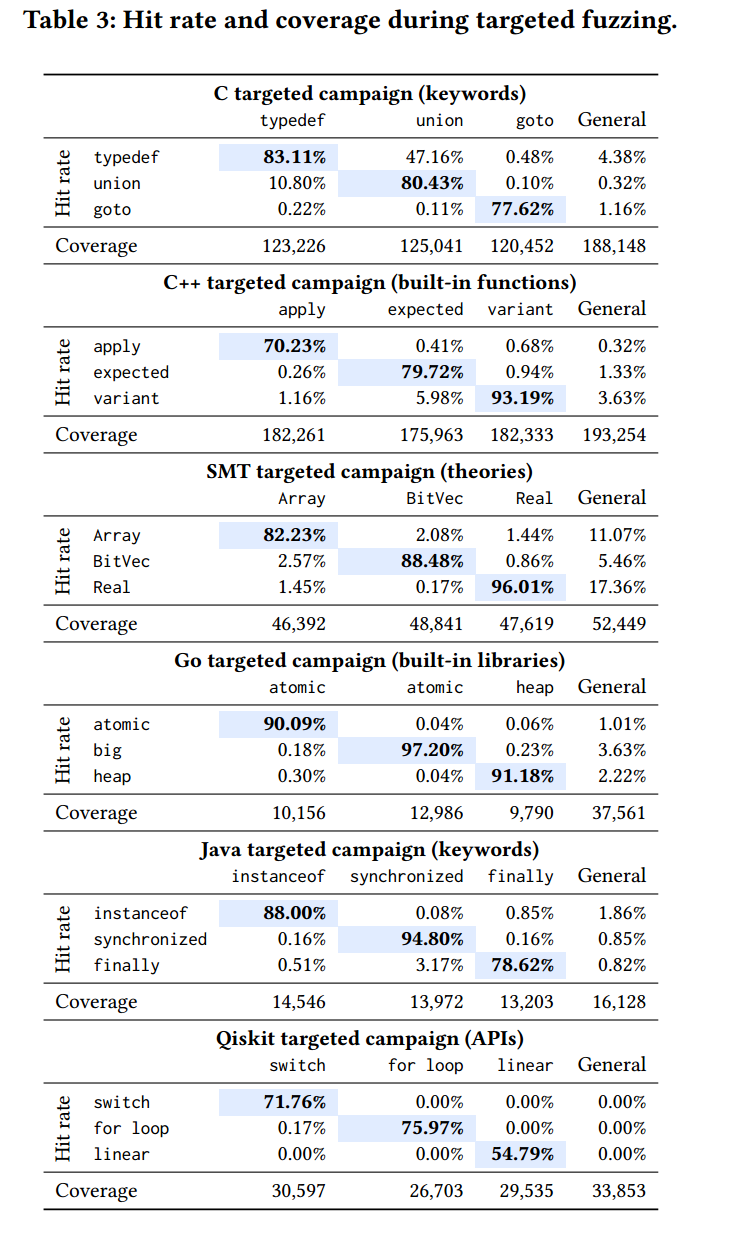
首先来简单解释下上面表格的含义,每一列代表针对某个语言的某一个特性进行模糊测试,如针对 C 中的 typedef 来进行特征模糊测试,来方便针对根据具体特征发现更多的 bug。表格中每一个具体的数值代表的是命中率,可以理解为生成的输入中能够满足某一特性的部分,同时,可以发现 Fuzz4All 在这一方面是有优势的,相较于 General 来说命中率少的可怜,但从覆盖路径这一角度来说传统模糊器在路径探索方面依然表现出不错的性能。
5.3 RQ3: Ablation Study
这一部分可以看做是灵敏度分析,通过简单的控制变量,来发现实验过程中采用的一些策略是否起了比较重要的作用。
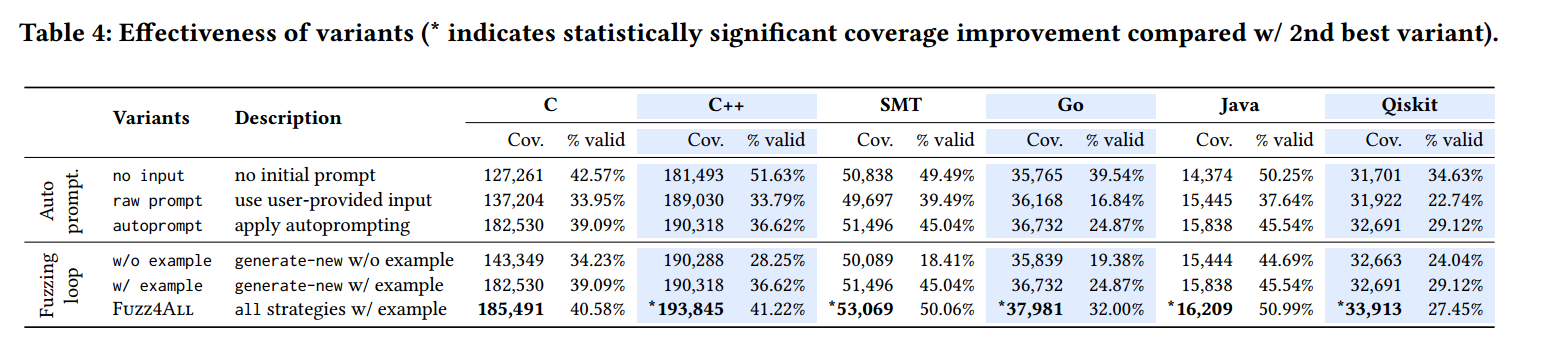
如上图所示,比如说在 AutoPrompting 阶段,定义了三种不同的类型实现,第一种是直接不提供 initial prompt。第二种是将用户提供的 input 直接作为 Fuzzing Loop 的输入,而不经过 DLLM 处理。第三种就是论文中所采用的阶段。
可以看到在探索路径上明显有了提高,这说明 DLLM 这一步还是有存在的必要的,但生成的有效输入占比上却出现了降低(笑)。
表格中下面的 Fuzzing Loop 分析也是同理,可以做参考。
5.4 RQ4: Bug Finding
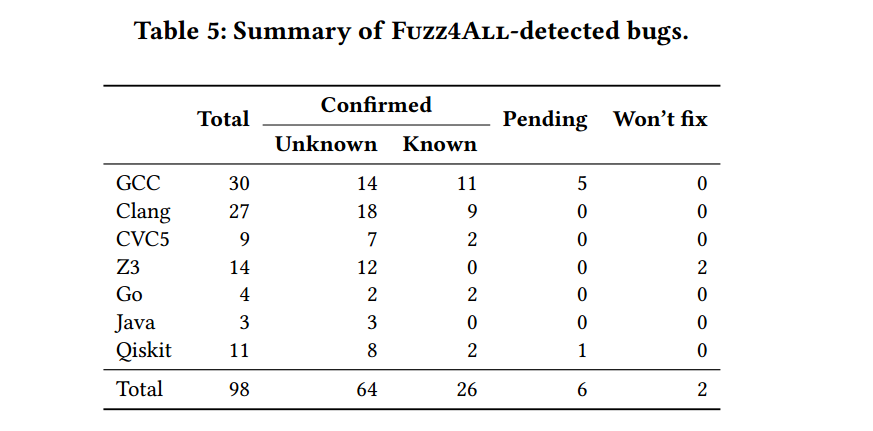
这是 Fuzz4All 总的一个 bug 产出,同时作者还列出了几个 Fuzz4All 具体的 bug 示例代码如下

从总体上可以看到这些代码是十分简洁的,但它们都有一个共同的特点,就是里面加入了很多针对目标语言和编译器的新特性,导致了 bug 的发现,这是其他模糊器没有的一个优点。
论文总结
这篇论文是发表在 ICSE 软工的一个顶会,文章比较突出的一个特点就是在传统 Fuzz 的过程上加上了 LLM 助力,这算是一个比较新颖的方式,这里提一下我认为这篇文章的优点:
- 在传统 Fuzz 加上了 LLM
- 在路径探索上表现出不错的效果
- 如论文的名字一样 Fuzz4All,实现了针对多个目标进行模糊测试
- 由于 LLM 的灵活性,Fuzz4All 可以根据当下的一些新特性来产生特定于其他模糊器的输入
同时我也认为基于这篇文章还有一些待挖掘的点(知识有限,一点拙见):
- DLLM 直接是由调用 GPT4 实现(fuzzing的能力受限于 GPT4 的一些具体的环境),是否可以训练出一套针对目标系统的 LLM,这样可能会在路径探索和有效性上表现得更好,同时也能发现更多的 bug
- 说是 Fuzz4All,但是实际上其本质还是在现有的模型上套了一层娃,连接了 fuzz 和 LLM 这两个部分,从某种程度上来说,我觉得这一部分可以尝试做的更好,以增强对目标体系的针对性。
- Title: 看论文 Fuzz4All Universal Fuzzing with Large Language Models
- Author: henry
- Created at : 2024-07-18 15:29:25
- Updated at : 2024-07-29 11:44:07
- Link: https://henrymartin262.github.io/2024/07/18/Fuzz4ALL/
- License: This work is licensed under CC BY-NC-SA 4.0.