static __always_inline voiddo_slab_free(struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsignedlong addr) { void *tail_obj = tail ? : head; structkmem_cache_cpu *c; unsignedlong tid; redo: /* * Determine the currently cpus per cpu slab. * The cpu may change afterward. However that does not matter since * data is retrieved via this pointer. If we are on the same cpu * during the cmpxchg then the free will succeed. */ do { tid = this_cpu_read(s->cpu_slab->tid); c = raw_cpu_ptr(s->cpu_slab); } while (IS_ENABLED(CONFIG_PREEMPT) && unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */ barrier();
if (likely(page == c->page)) { void **freelist = READ_ONCE(c->freelist);
set_freepointer(s, tail_obj, freelist); //被当前 active page 回收
if (unlikely(!this_cpu_cmpxchg_double( s->cpu_slab->freelist, s->cpu_slab->tid, freelist, tid, head, next_tid(tid)))) {
/* * Slab cache management. */ structkmem_cache { structkmem_cache_cpu __percpu *cpu_slab; /* Used for retrieving partial slabs, etc. */ slab_flags_t flags; unsignedlong min_partial; unsignedint size; /* The size of an object including metadata */ unsignedint object_size;/* The size of an object without metadata */ unsignedint offset; /* Free pointer offset */ #ifdef CONFIG_SLUB_CPU_PARTIAL /* Number of per cpu partial objects to keep around */ unsignedint cpu_partial; #endif structkmem_cache_order_objectsoo;
/* Allocation and freeing of slabs */ structkmem_cache_order_objectsmax; structkmem_cache_order_objectsmin; gfp_t allocflags; /* gfp flags to use on each alloc */ int refcount; /* Refcount for slab cache destroy */ void (*ctor)(void *); unsignedint inuse; /* Offset to metadata */ unsignedint align; /* Alignment */ unsignedint red_left_pad; /* Left redzone padding size */ constchar *name; /* Name (only for display!) */ structlist_headlist;/* List of slab caches */
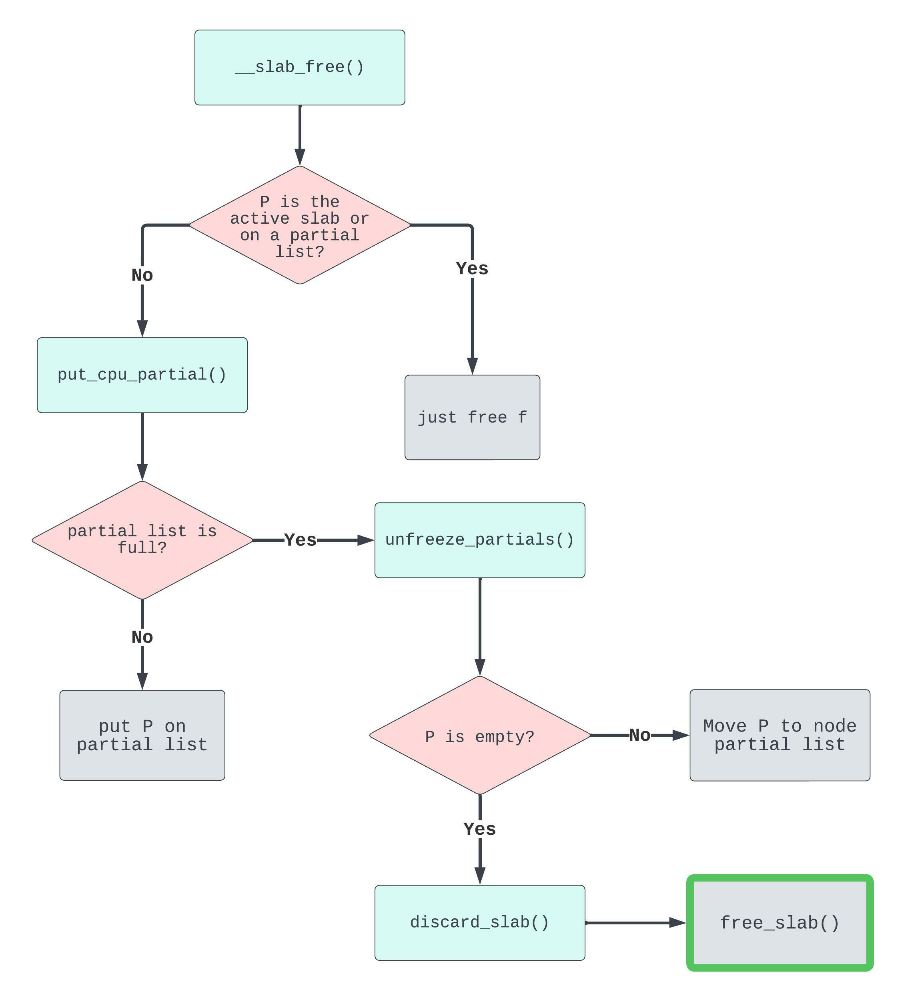
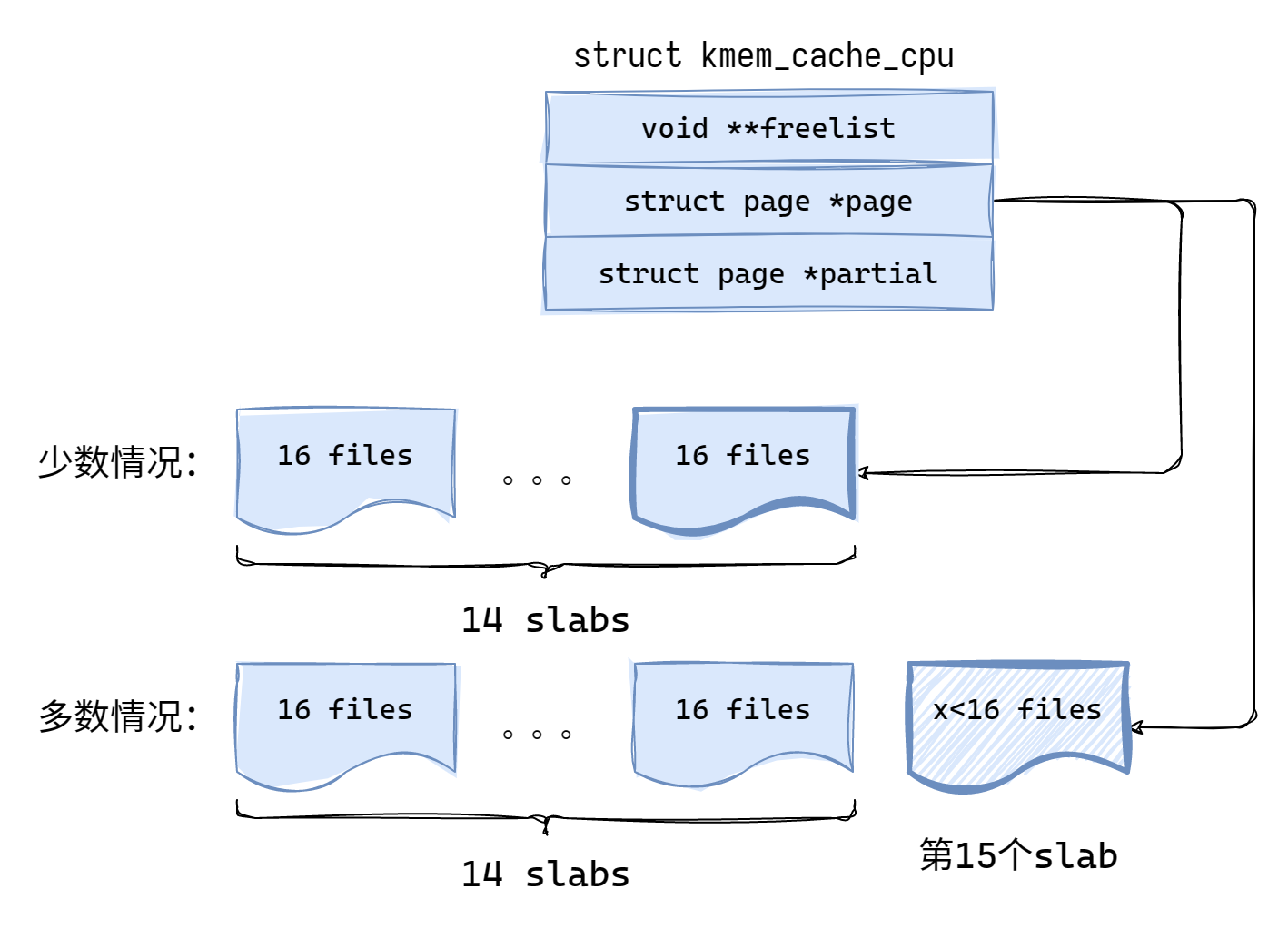
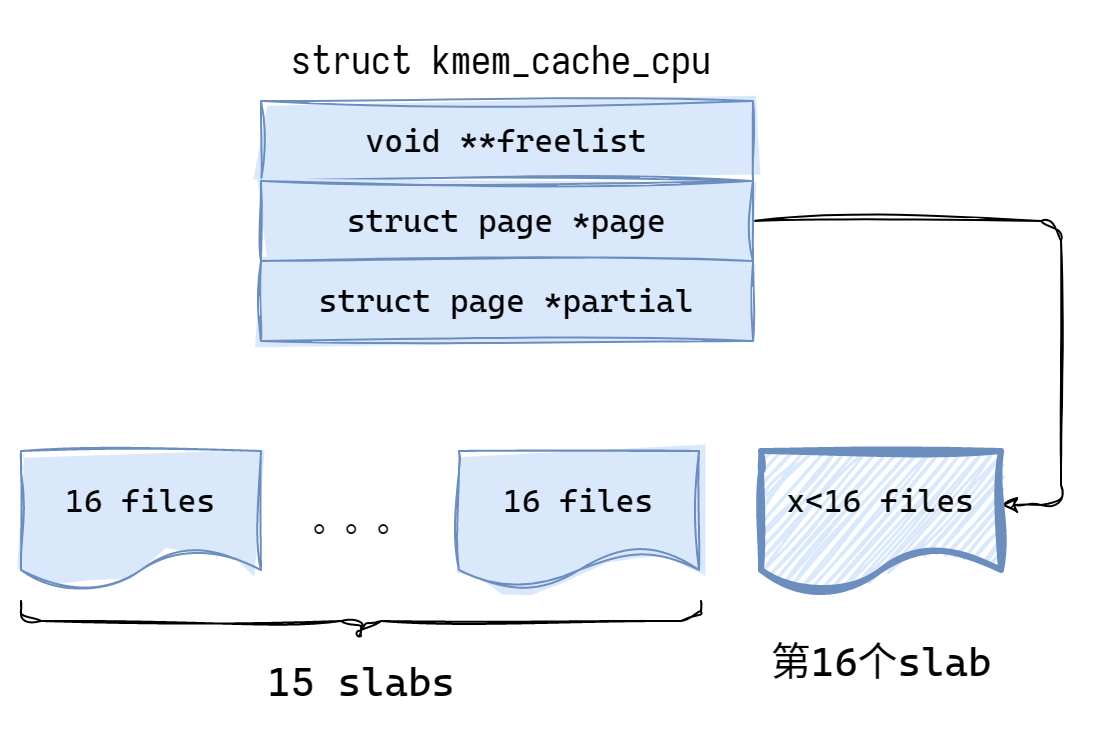
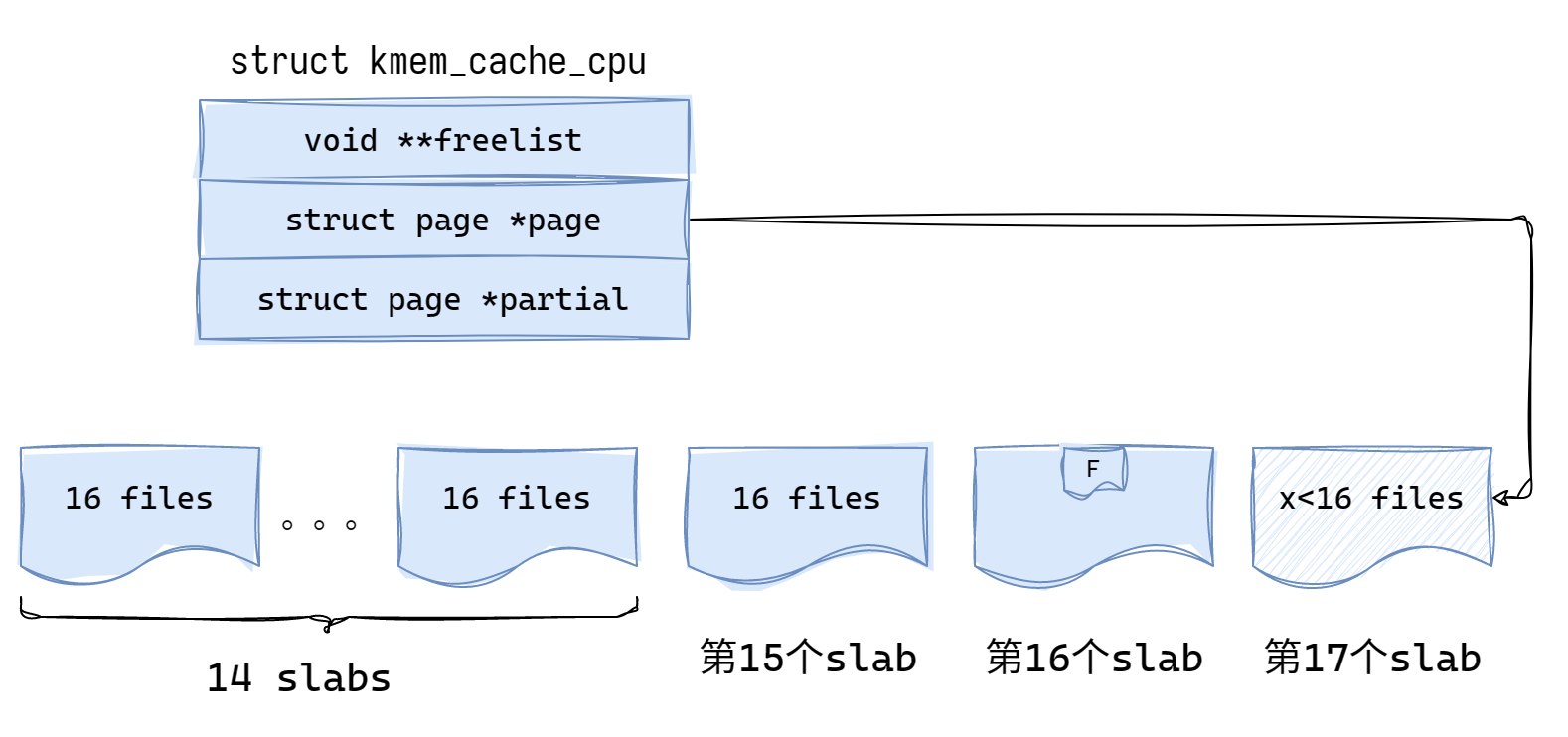
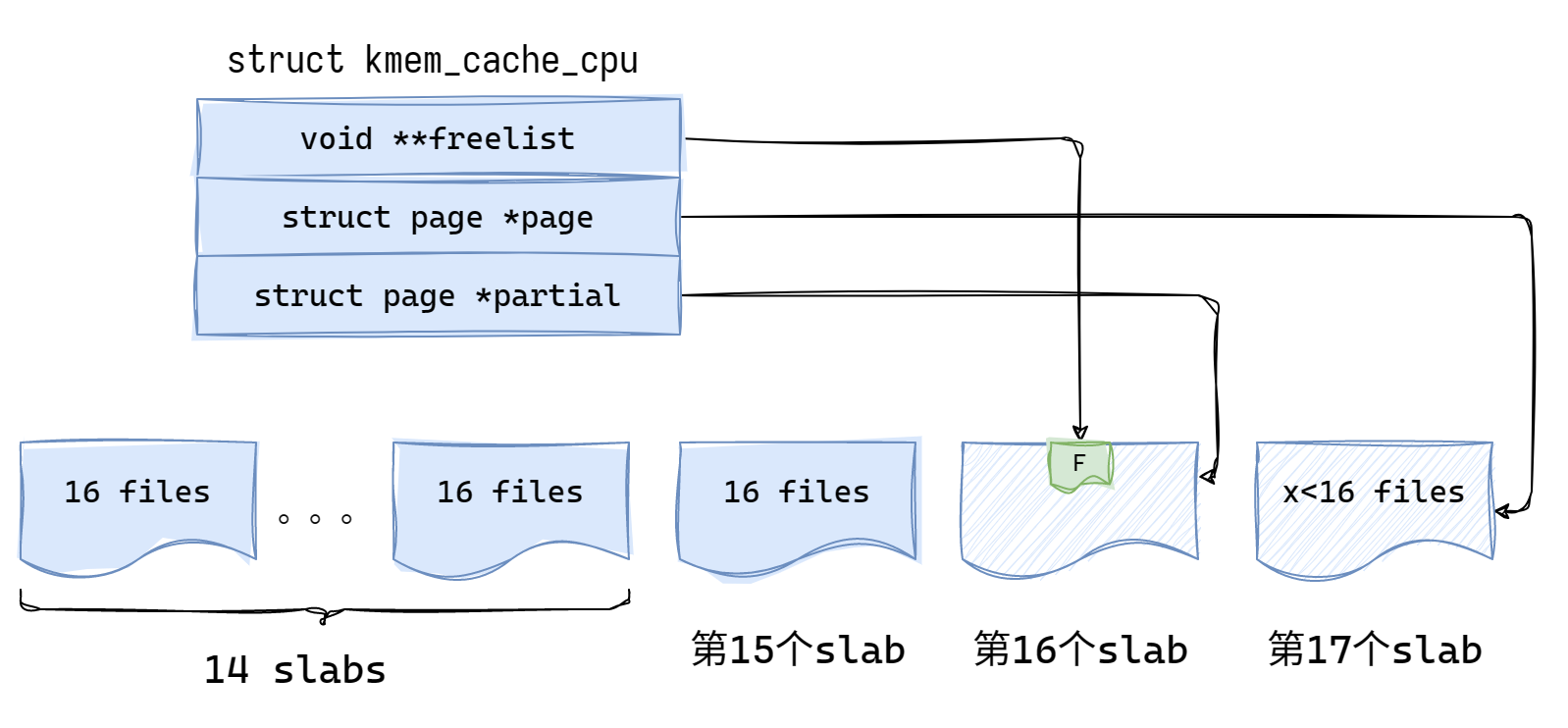
kmem_cache_cpu 中的 page 即为前面提到的 active page,freelist 是这个 active page 中的 freelist 指针,partial 中存放的是非满的 page。
1 2 3 4 5 6 7 8 9 10 11
structkmem_cache_cpu { void **freelist; /* Pointer to next available object */ unsignedlong tid; /* Globally unique transaction id */ structpage *page;/* The slab from which we are allocating */ #ifdef CONFIG_SLUB_CPU_PARTIAL structpage *partial;/* Partially allocated frozen slabs */ #endif #ifdef CONFIG_SLUB_STATS unsigned stat[NR_SLUB_STAT_ITEMS]; #endif };
if (kmem_cache_has_cpu_partial(s) && !prior) { new.frozen = 1; // 需要执行这一步
} else { /* Needs to be taken off a list */
n = get_node(s, page_to_nid(page)); spin_lock_irqsave(&n->list_lock, flags);
} }
} while (!cmpxchg_double_slab(s, page, prior, counters, head, new.counters, "__slab_free"));
if (likely(!n)) {
/* * If we just froze the page then put it onto the * per cpu partial list. */ if (new.frozen && !was_frozen) { //前面的 new.frozen 在这里起作用 put_cpu_partial(s, page, 1); //需要执行到这一步 stat(s, CPU_PARTIAL_FREE); } /* * The list lock was not taken therefore no list * activity can be necessary. */ if (was_frozen) stat(s, FREE_FROZEN); return; } //.... }